?系统配置
首选操作系统
Red Hat Enterprise Linux (RHEL)是首选操作系统。应该使用最新的受支持的主版本,当前是RHEL 6。
文件系统
XFS是Greenplum数据库数据目录的最佳实践文件系统。XFS应该用下列选项挂载:

端口配置
ip_local_port_range应该被设置为不与Greenplum数据库端口范围冲突。例如:

I/O配置
在含有数据目录的设备上,blockdev预读尺寸应该被设置为16384。

应该为所有数据目录设备设置死线IO调度器。

应该在/etc/security/limits.conf文件中增加OS文件和进程的最大数量。

让内核文件输出到一个已知的位置并且确保limits.conf允许内核文件。

OS内存配置
Linux中sysctl的变量vm.overcommit_memory和vm.overcommit_ratio反映了操作系统管理内存分配的方式。这些变量应该按照下面的方式设置:
vm.overcommit_memory决定OS用于确定为进程可以分配多少内存的方法。这个变量应该总是被设置为2,它是对数据库唯一安全的设置。
vm.overcommit_ratio是被用于应用进程的RAM的百分数。在Red Hat Enterprise Linux上默认是50。
不要启用操作系统的中的巨型页。
共享内存设置
Greenplum数据库使用共享内存在postgres进程之间通信,这些进程是同一个postgres实例的组成部分。下面的共享内存设置应该在sysctl中设定并且很少会被修改。
验证操作系统
运行gpcheck以验证操作系统配置。请见Greenplum数据库工具指南中的gpcheck。
每台主机上的Segment数量
每台Segment主机上执行的Segment数量的确定对总体系统性能有着巨大的影响。这些Segment与彼此以及主机上的其他进程共享该主机的CPU核心、内存和网络接口。过高估计一台服务器能容乃的Segment数量是导致非最优性能的常见原因。
在选择每台主机上运行多少Segment时必须要考虑的因素包括:
核心数量
安装在该服务器上的物理RAM容量
NIC数量
附加到服务器的存储容量
主Segment和镜像Segment的混合
将在主机上运行的ETL进程
运行在主机上的非Greenplum进程
Segment内存配置
gp_vmem_protect_limit服务器配置参数指定单个Segment的所有活动postgres进程在任何给定时刻能够消耗的内存量。可使用下面的计算为gp_vmem_protect_limit估计一个安全值。
1,使用这个公式计算gp_vmem(Greenplum数据库可用的主机内存):
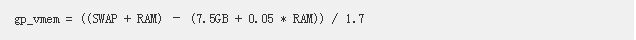
其中 SWAP是主机的交换空间(以GB为单位)而RAM是主机上安装的RAM(以GB为单位)。
2,计算max_acting_primary_segments。当镜像Segment由于集群中其他主机上的Segment或者主机失效而被激活时,这是能在一台主机上运行的主Segment的最大数量。例如,对于布置在每台主机有8个主Segment的四主机块中的镜像来说,单一Segment主机失效将会在其所在块中剩余每台主机上激活2个或者3个镜像Segment。这一配置的max_acting_primary_segments值是11(8个主Segment外加3个失效时激活的镜像)。
3,通过将总的Greenplum数据库内存除以活动主Segment的最大数量来gp_vmem_protect_limit:

转换成兆字节就是gp_vmem_protect_limit系统配置参数的设置。
对于有大量工作文件产生的场景,可调整gp_vmem的计算以考虑工作文件:

有关监控和管理工作文件使用的信息请见Greenplum数据库管理员指南。
用户可以从gp_vmem的值计算操作系统参数vm.overcommit_ratio的值:

语句内存配置
gp_statement_mem服务器配置参数是分配给Segment数据库中任何单个查询的内存量。如果一个语句要求额外的内存,它将溢出到磁盘。用下面的公式计算gp_statement_mem的值:
(gp_vmem_protect_limit * .9) / max_expected_concurrent_queries
例如,如果gp_vmem_protect_limit被设置为8GB(8192MB),对于40个并发查询,gp_statement_mem的计算可以是:
(8192MB * .9) / 40 = 184MB
在每个查询被溢出到磁盘之前,它被允许使用184MB内存。
要安全地增加gp_statement_mem,用户必须增加gp_vmem_protect_limit或者减少并发的查询数量。要增加gp_vmem_protect_limit,用户必须增加物理RAM或者交换空间,也可以减少每台主机上的Segment数量。
注意在集群中增加Segment主机无助于内存不足错误,除非用户使用额外的主机来减少每台主机上的Segment数量。
弄明白溢出文件是什么。然后覆盖gp_workfile_limit_files_per_query。用配置参数gp_workfile_limit_files_per_query可以控制每个Segment上每个查询创建的溢出文件的最大数量。然后交代gp_workfile_limit_per_segment。
溢出文件配置
如果查询没有被分配足够的内存,Greenplum数据库会在磁盘上创建溢出文件(也被称为工作文件)。默认单个查询可以创建不超过100,000个溢出文件,这对大部分查询来说都是足够的。
用户可以用配置参数gp_workfile_limit_files_per_query控制每个查询和每个Segment创建的溢出文件最大数量。设置该参数为0将允许查询创建无限个溢出文件。限制允许的溢出文件数量可以防止失控的查询干扰系统。
如果一个查询没有被分配足够的内存或者被查询数据中存在数据倾斜,查询可能会生成大量溢出文件。如果查询创建超过指定数量的溢出文件,Greenplum数据库会返回这个错误:
ERROR: number of workfiles per query limit exceeded
在提升gp_workfile_limit_files_per_query之前,尝试通过更改查询、改变数据分布或者更改内存配置来降低溢出文件的数量。
gp_toolkit方案包括一些视图可以允许用户查看所有正在使用溢出文件的查询的信息。这些信息可以被用来排查故障以及查询调优:
gp_workfile_entries视图中为每一个当前在某个Segment上使用工作文件的操作符包含一行。
gp_workfile_usage_per_query视图为每一个当前在某个Segment上使用工作文件的查询包含一行。
gp_workfile_usage_per_segment视图为每个Segment包含一行。每一行显示当前在该Segment上用于工作文件的磁盘空间总量。
gp_workfile_compress_algorithm配置参数指定应用于溢出文件的压缩算法。它的值可以是none或者zlib。在使用溢出文件时,设置这个参数为zlib可以提高性能。
如果一个查询没有被分配足够的内存或者被查询数据中存在数据倾斜,查询可能会生成大量溢出文件。如果查询创建超过指定数量的溢出文件,Greenplum数据库会返回这个错误:
ERROR: number of workfiles per query limit exceeded
在提升gp_workfile_limit_files_per_query之前,尝试通过更改查询、改变数据分布或者更改内存配置来降低溢出文件的数量。
京ICP备09015132号-996 | 网络文化经营许可证京网文[2017]4225-497号 | 违法和不良信息举报电话:4006561155
© Copyright 2000-2023 北京哲想软件有限公司版权所有 | 地址:北京市海淀区西三环北路50号豪柏大厦C2座11层1105室







![网络文化经营许可证京网文[2017]4225-497号](/f/image/20180509/20180509164113_9707.jpg){kind=link}