人们普遍认为,在佛罗里达州度过2020年春假的学生和其他人帮助COVID-19在美国和其他地方广泛传播(另见本研究)。2021年的情况在几个方面完全不同。首先,这种疾病已经在美国出现了一年多,大约30%的人口在之前的曝光中拥有抗体。另外,现在有几种疫苗在使用,在编写本报告时,有近20%的人至少接受过一次接种。(由于这两个群体有重叠,所以相信总数约占总人口的45%)。我们现在知道,16岁以下的儿童不会大量感染该病,不是该病传播的主要媒介。社会上的疏导行为都在不同程度的使用,目前全国各地的感染人数都在下降。据信,这是由于免疫力的提高和非药物干预措施(NPIs),如社交距离和口罩的使用。
众所周知,房间里的大象是SARS-CoV-2的几个新变种的出现,它们都具有不幸的特征。新的变种似乎比最初形式的病毒更具传染性。有些变种似乎能更好地躲避因接触前一种病毒而形成的抗体。有人担心,有些病毒可能不那么容易被至少一些现有的疫苗所对付(这是最近一项研究的主题)。在它们首次出现的地方,它们似乎都已经成为病毒库中最流行的形式。这些小动物被称为关注变种(VoC)是有原因的。我在这里列出了正在研究的变种,使用基因组名称,然后在括号中列出原产地(对应于每个变种的通常名称)。它们是B.1.1.7(英国/联合王国)、B.1.351(南非)、B.1.427和B.1.429(南加州)、P.1(巴西玛瑙斯)和B.1.526(纽约市)。
由于我们现在开始了新的春假季节,从这些变体来看来自佛罗里达的图片是及时的。然而,我不能给出当前的观点。我的数据来自GISAID的SARS-CoV-2基因组序列库,因为它是所有研究者都能获得的最大的序列(NCBI的GenBank也不错,可以直接访问Wolfram Data Repository中策划的SARS-CoV-2序列)。由于标本采集、实验室测序和最终上传到GISAID之间的滞后时间,这些数据必然不包括当前或最近收集的序列。通常情况下,过去三周的样本很少,过去两周的样本几乎没有。我将展示的是我们从2月中旬到2月底的前景。
这些变体具有特定(重迭)变异集的特征。当然,黄金标准(用于分类)是在给定序列中检测其中一组突变。为此,人们需要仔细了解需要寻找的内容。搜索可以在"喧闹"的环境中进行:其他突变可能在附近,一些特征突变本身可能因进一步突变而稍有改变,等等。我没有资源去驾驭这样的滩涂。相反,我依赖一种通用的基因组比较方法,这种方法恰好能够很好地实现当前的目的。
方法概要
这使我们对这里用于分析SARS-CoV-2的基因组序列的策略进行了简要的描述。回顾一下,遗传DNA和RNA序列可以被描述为由四个字母(A,C,G,T)组成的字符串,在RNA序列中使用U代替T。这些字母对应于腺嘌呤、鸟嘌呤、胞嘧啶和胸腺嘧啶/尿嘧啶四种核苷酸。序列可以使用直接的字符串比较计算进行比较。这些都是对齐方法。宽泛地说,避免直接串比较的技术属于被称为 "无对齐方法 "的家族。后者通常享有更好的速度和通用性的优势,但代价是通常会提供一些较弱的结果。我的方法是从一种叫做混沌游戏表示法(CGR)的东西开始的,在这种方法中,基因序列被说明为类似分形的方形图像。这种方法是乔尔-杰弗里(Joel Jeffrey)在三十年前首创的,并一直在不断完善。许多从业者,包括我自己在内,如今都在使用一种被称为频率混沌游戏表示法(FCGR)的版本。
当人们有了遗传序列的图像后,仍然存在如何比较的问题。对于FCGR来说,涉及到一个像素化级别,它决定了图像的大小:在级别 上有
上有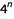 像素。我的典型设置是将
像素。我的典型设置是将 设置为7或8,所以这就是16K或64K像素(这里我使用常见的惯例,1K是
设置为7或8,所以这就是16K或64K像素(这里我使用常见的惯例,1K是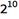 ,或1024)。换个说法,在像素化水平为8时,图像是256×256。
,或1024)。换个说法,在像素化水平为8时,图像是256×256。
我给大家看几张这样的图片,是从之前Wolfram社区的一个帖子中摘录的(我忘了具体是哪一张):

比较具有 64K 元素的对象是一项艰巨的任务,我们并没有尝试这样做。相反,我们使用两种相当常见的维度减少方法,将这些维度降低到一个更容易管理的大小。
首先,我们使用离散余弦变换(DCT)来剔除图像中的高频成分。这样做的效果是通过去除 "嘈杂 "的高频来对图像进行粗粒度处理。有人可能会问,为什么我们不简单地使用粗粒度的FCGR图像。答案是,这些图像的效果根本不如去除高频成分的更精细的FCGR图像。在任何情况下,我的典型设置将保留原始256×256 FCGR图像的32×32频率分量阵列。
一旦我们有了一组使用DCT减维的这些图像,下一步就是使用一种被称为主成分分析(PCA)的方法,它又是基于一种被称为奇异值分解(SVD)的线性代数矩阵函数。下面是前一对经过维度还原步骤后的样子(并进行了一些操作,将它们重新创建为图像):

到目前为止,这篇文章已经是大量的技术术语。有兴趣的读者可以看看我在2019年底发表的关于这个主题的文章(有图片和算法复杂度分析),进行详细的阐述。同一天(12月30日),路透社发表了一篇文章,报道了中国武汉异常爆发的一种类似肺炎的疾病。于是,我有了一套工具,并且在短短几周内,一个病毒爆发产生的数据,可以在上面应用。一些更驯服的东西会更受欢迎,但我们并不总是可以选择。
我要指出,关于使用基于FCGR的方法对SARS-CoV-2基因组进行分类的文献越来越多。我在Wolfram社区上的一系列文章中也做了这样的工作(参见 "基因组分析与SARS-CoV-2"、"从SARS-CoV-2基因组测序到系统发育树"、"分析SARS-CoV-2变种在加州的传播 "和 "分析SARS-CoV-2变种在佛罗里达的传播")。但我绝不是唯一做这种事情的人。我所做的或许是新颖的,就是证明这些方法可以检测到变异水平的差异。例如,已发表的论文显示了基因组如何在沙贝科罗那病毒家族中的位置,但那些使用FCGR的论文并没有(据我所知)试图比较和/或聚类SARS-CoV-2的不同变体。
对关注的变种进行分类
作为参考,我从GISAID下载的序列是在2021年某些时间段收集的五个变体的集合。我们的想法是确定它们是相当近期的(事实上,其中一个变体是在2021年才确定的),并使用足够的时间段来获得每个变体的200-400个样本。我还下载了2月份在佛罗里达州连续三个时间段收集的三组数据。GISAID要求对从该网站使用的基因序列提供适当的归属收集和测序实验室和研究人员(而且,相当有帮助的是,他们有一种自动获取这些数据的方法,作为格式化的PDF文件)。我在本篇文章的笔记本版本中包含了有此内容的单元格。
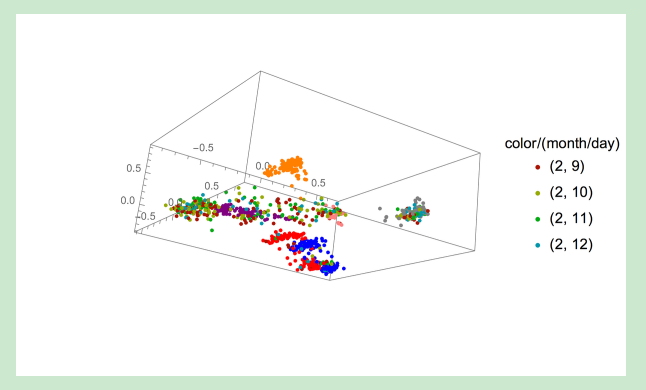
首先,我给大家看一下几个变异的图片。每个点代表一个特定的基因组序列。这些数据点是通过又一轮降维获得的,这次是用一种称为多维缩放(MDS)的方法降维到3D:

重点在这。即使从基因组序列(在SARS-CoV-2的情况下,由近3万个核苷酸组成)还原到3D载体后,仍然有足够的信息含量来辨别几个变异体非常明显的聚类。看似例外的情况(红/蓝混杂)来自两个近亲,共同构成了加州变体。
也有少量的离群值。这并不十分令人惊讶。首先,对变异状态并不重要的噪声突变会对这些变异出现在3D图像中的位置产生一定影响。另外,每一个参考序列都是完美的分类也不是一定的。而且,有些人可能在没有拥有其变异体特有的所有突变的情况下就被分类了,这也是有可能的。例如,当使用遗传标记测试进行分类时,这种情况可能发生。
我应该提到,有很多有用的方法可以减少维度。事实上,Mathematica函数DimensionReduce中就内置了几种方法。其中一种方法称为潜在语义分析(LSA),是MDS的表亲。但我更喜欢后者,虽然它不能(目前)通过DimensionReduce获得,但在Wolfram函数库中有一个现成的MultidimensionalScaling版本。
2月9日至12日佛罗里达序列
为了表明哪些序列可能属于变异类,我将创建所谓的系统发育树,这是基于遗传接近度测量的树枝图。什么是树状图?请看一下函数Dendrogram的文档。需要提醒读者的是,这篇博客的剩余部分很可能是单调的,因为它主要只是这些树状图。根据我的经验,单调是数据分析的规则。但可以搜集到有用的信息,这才是真正重要的。
首先,我展示另一个MDS图。这一次,我将变异序列减去了3倍,以避免杂乱无章(当我们看树时,这一点将更加重要)。我试图展示一个观察角度,以合理准确地了解来自佛罗里达州的哪些序列似乎在变体中聚集。人们在B.1.1.7(灰色)序列中看到了几个,同样,蓝色和红色也是如此。这种情况似乎也发生在紫色和粉色群中。我们将看到,最后这两个有点误导性。发生的情况是,三个维度并不总是足以分离非相关序列。(当然,人们可以使用强调非重叠方面的三维图像,但这相当于使用了六个维度,而且仍然难以可视化)。
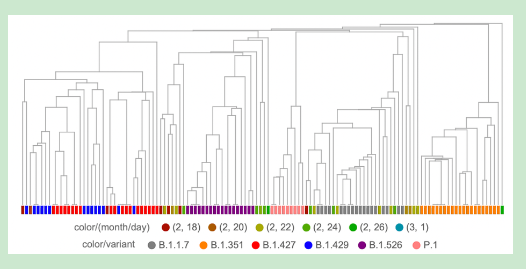
系统进化树
系统进化树图可以更好地了解序列是否相关。除了放置的近似性,还有将给定的一对序列与其最接近的共同分支点分开的树枝长度。我们在下面的树中利用了这一点。在这里,为了可读性,我们将变异体的数量减少了6倍(我已经翻阅了使用较少减法的树--但佛罗里达序列在变异体之间的聚类和相对分支长度并没有太大的变化)。
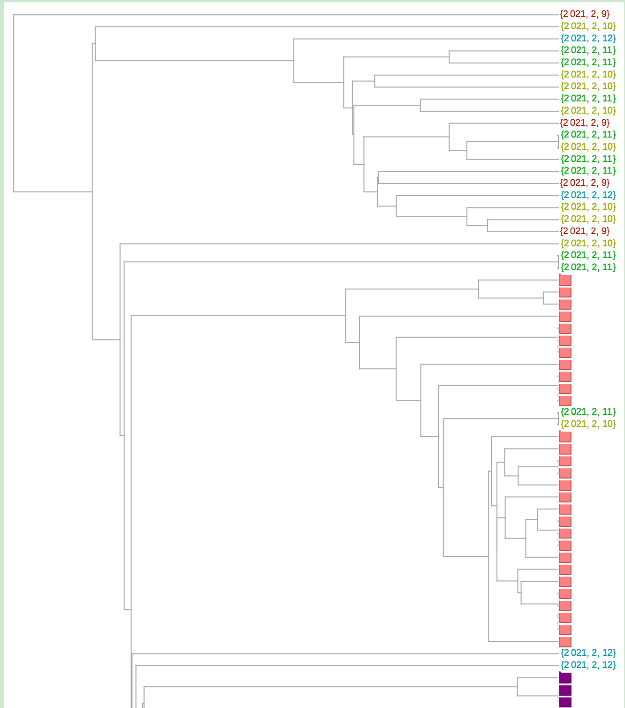
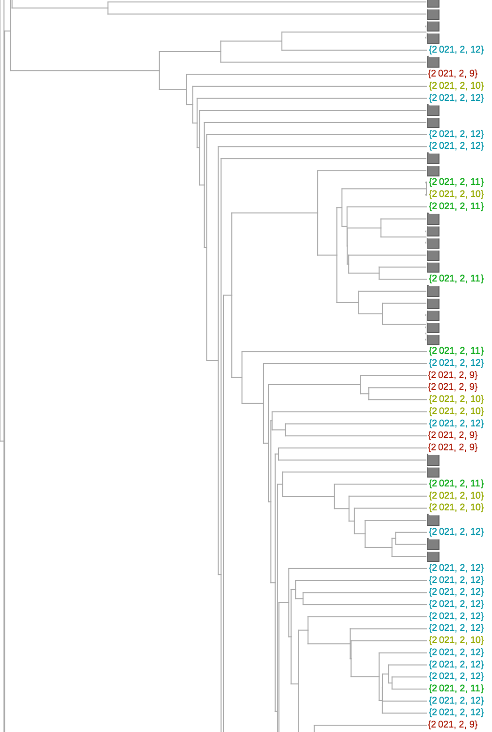
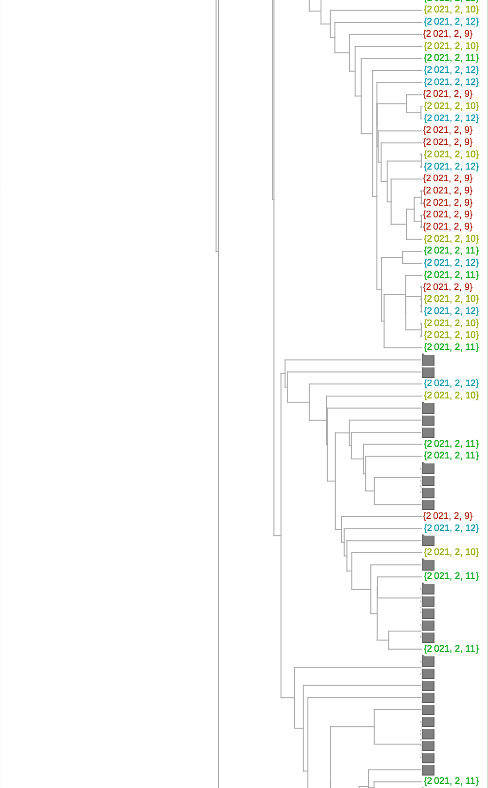
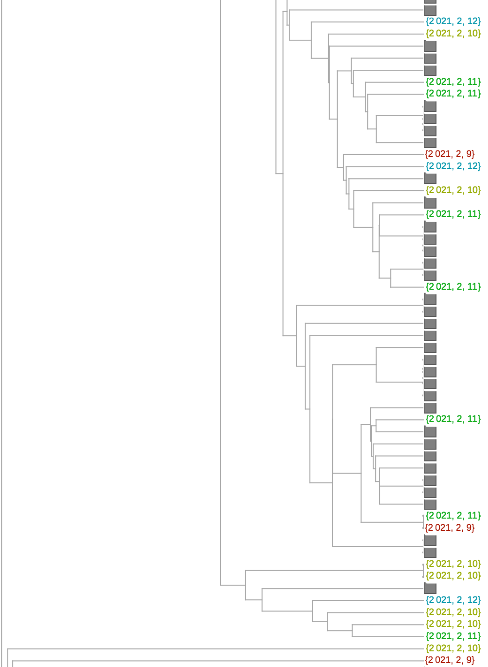
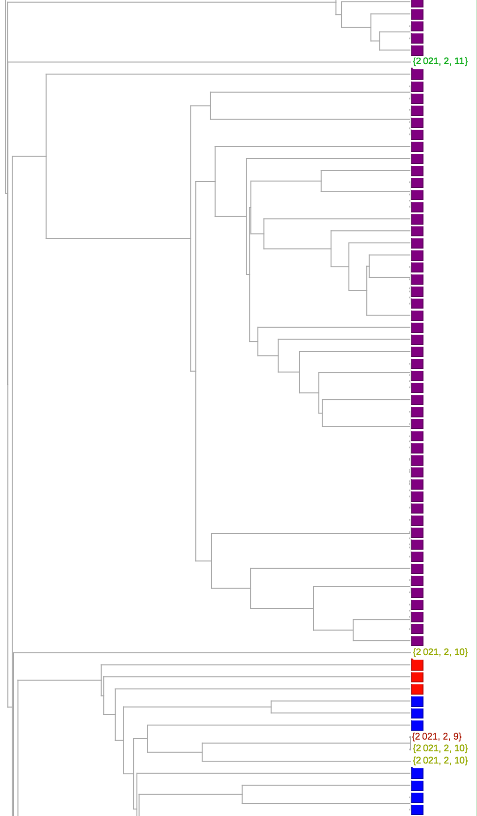
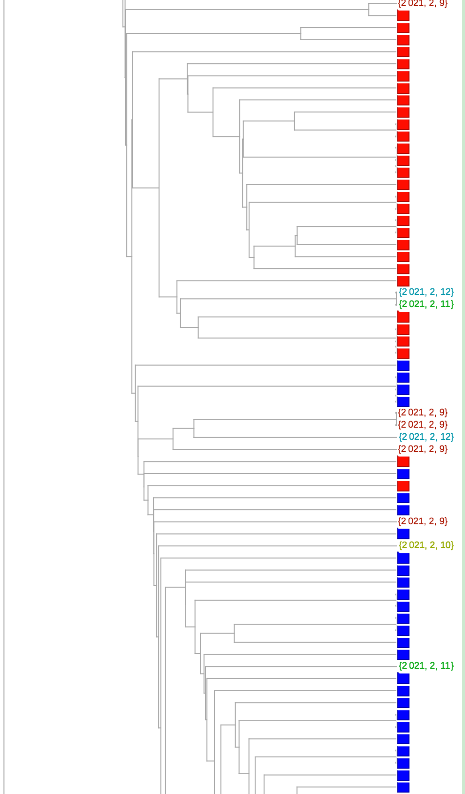
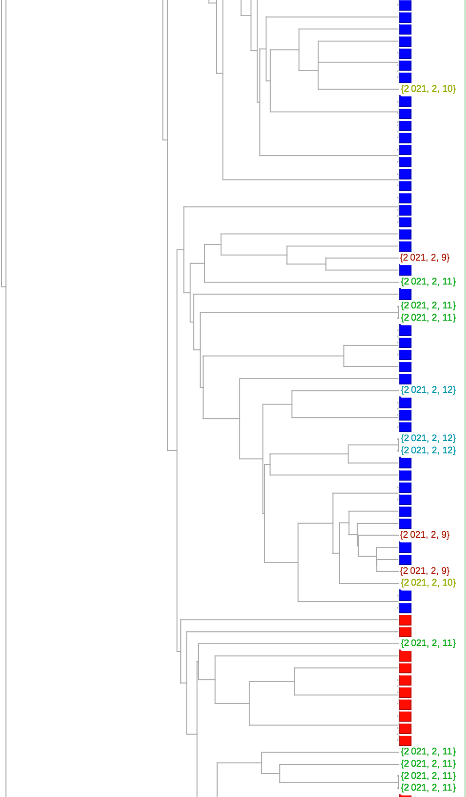
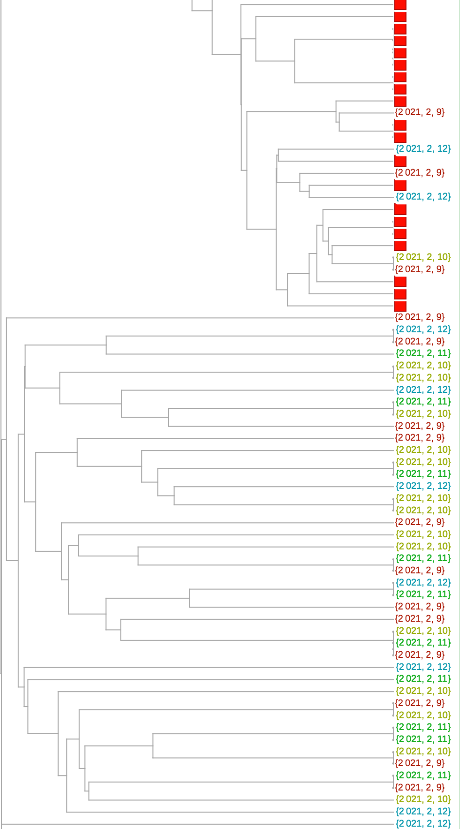
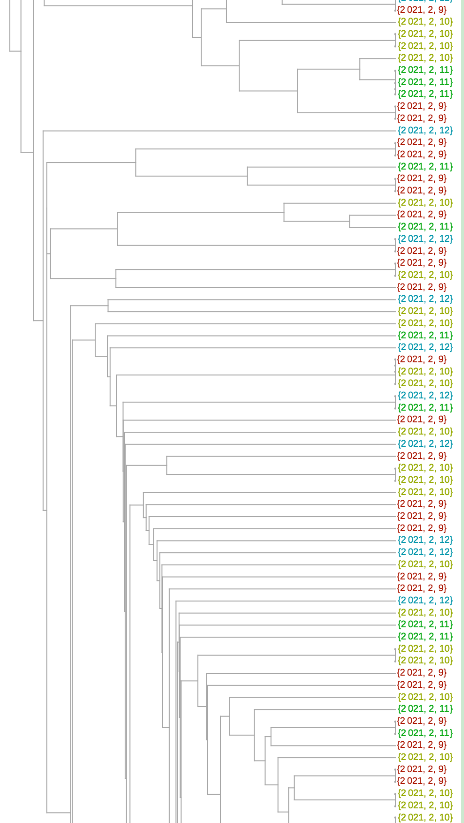

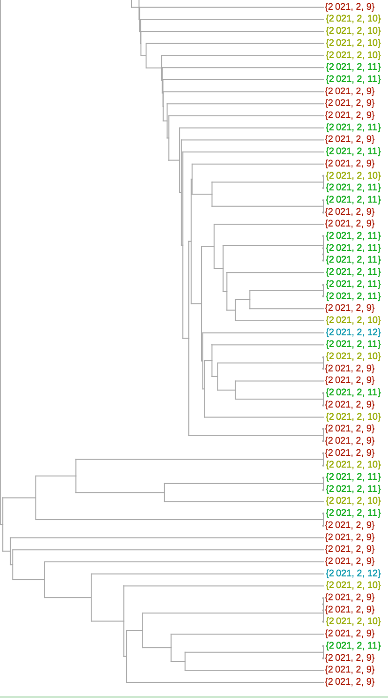
只有两个序列聚集在粉红色的P.1变体中。可能与紫色1.526变体在一起的那一个确实有一个太长的分支,不能认为它有可能是那个变体(虽然这只是一个启发式的说法,我不会说是肯定的)。我自己的估计是,84是可信的B.1.1.7变体,35是加州变体中的一个或其他类。总的来说,这相当于2月9日至12日期间收集的佛罗里达州序列的29%左右。
2月13-17
我们在几天的时间里,分析2月13日至17日期间在佛罗里达州收集的SARS-CoV-2序列:
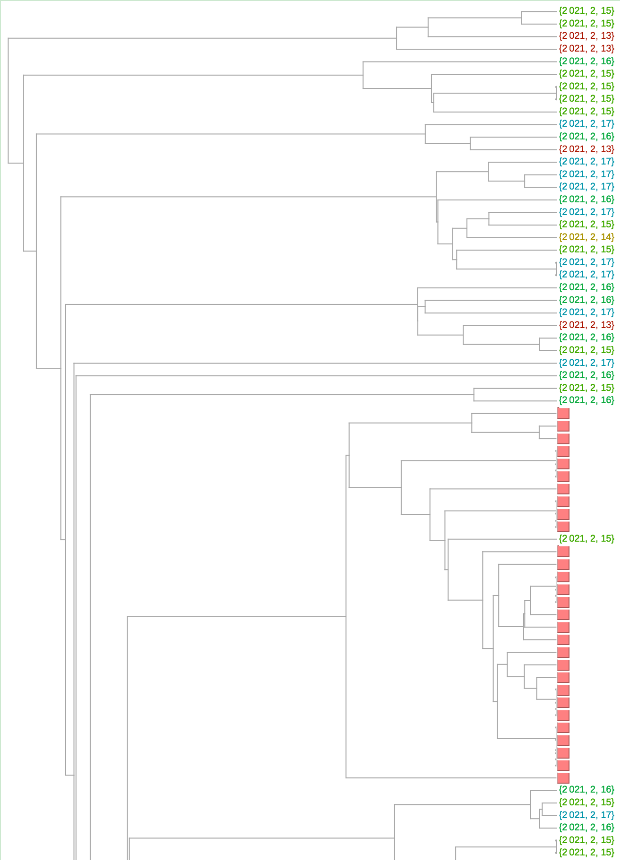



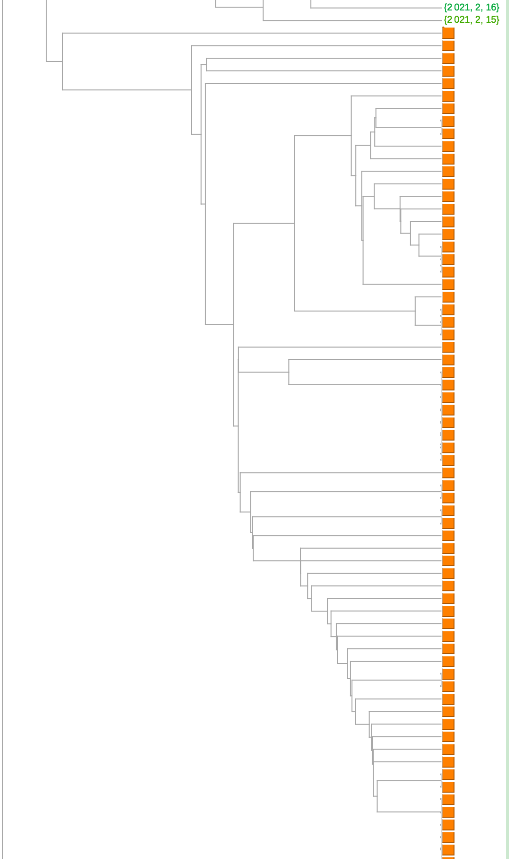


目测,我看到P.1和B.1.526变体各一个,B.1.427/B.1.429变体32个,B.1.1.7变体56个。从我们的测试集来看,总共有292个,所以这次约有31%的数量是由变体组成的。
2月18日 继续
最近的一组是在2月18日或之后收集的,由270个序列组成。除17个以外,所有其他序列都是在2月25日之前收集的,因此在编写本报告时(3月16日),这组序列是三个多星期前收集的。



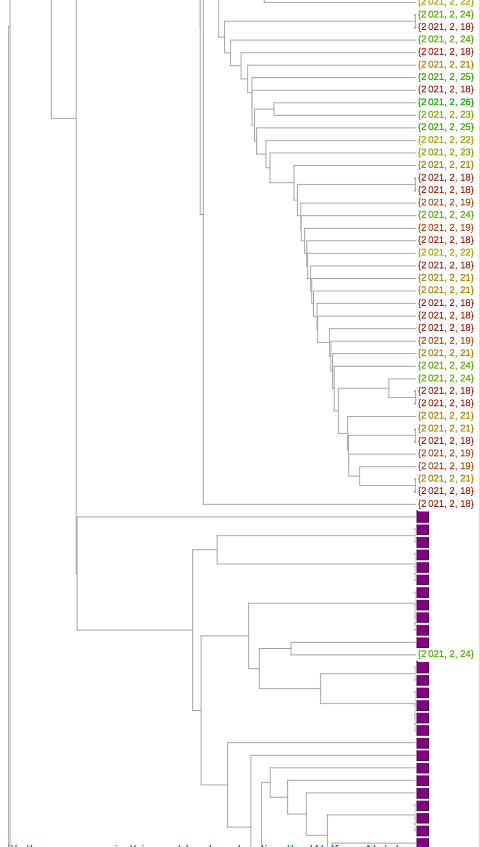
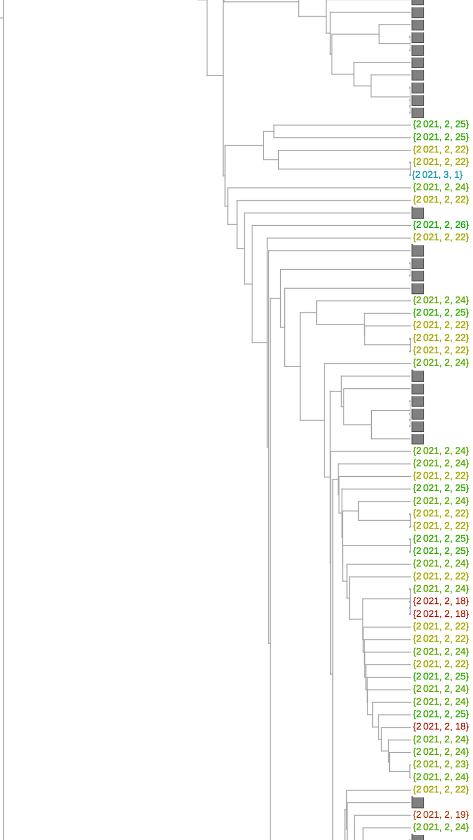


现在看来,P.1和B.1.526变体分别有3个和5个。至少有26个似乎来自B.1.427/B.1.429系列。现在有63个来自B.1.1.7变体。这相当于36%是由变种组成的。
我们已经看到了一个上升的趋势,在2月份在佛罗里达州的变体的百分比。这并不是非常出乎意料;流行病学家已经预测到会发生这种情况。目前,根据基因标记测试等数据(这比GISAID提供的数据要新),据说B.1.1.7变异体占佛罗里达州目前所有病例的36%,相信在不久的将来会达到50%。我所展示的可以看作是佐证,但要注意的是,其他一些变种(特别是来自加利福尼亚的变种)也在增加。此外,最近的新闻称,佛罗里达州每天新确诊的病例总数已经停止了下降,甚至可能还在小幅上升(目前是五千左右)。这不是一个很好的情况。从好的方面看,春假给佛罗里达带来的涌入量比去年要少,而且这次有一部分人(包括许多最脆弱的人)会在假期后人口外流接受过疫苗接种。






