
技术继续改变业务。 Refinitiv 一直在寻求利用技术使我们在业务过程中收集的信息更具相关性和个性化,并更快地将其交付给我们的客户和员工。 通过使用共享平台并跨业务部门工作,我们希望让我们的员工更容易访问和洞察我们的数据,无论他们如何访问数据。
为了促进这种方法,我们希望创建一个复杂的业务分析和智能 (BA/BI) 平台,为所有 Refinitiv 员工提供所有内容的单一视图。 这是一个相当大的挑战,因为我们必须整合许多包含不同结构的半相关数据的不同数据源,以满足多个部门和角色的各种需求和要求。
对于数据访问和管理,很明显我们需要一个快速、无模式的数据存储来处理我们的 BA/BI 应用程序中越来越多的非结构化数据。 我们的应用程序使用了二十多个数据源,提供了各种信息。 这需要一种强大的查询语言,能够表达我们的员工希望快速回答的广泛问题。
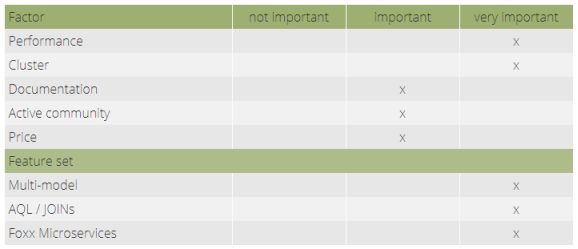
一个关键要求是支持临时连接和图遍历,以便为应用程序的不同部分使用正确的数据访问策略,并能够提出更多问题。 我们的首选将是具有活跃且响应迅速的社区的开源解决方案。
首先,ArangoDB 是一个真正的开源项目,拥有对开发人员友好的 Apache 2 许可证。此外,我们认为其背后的团队很有帮助且透明。经过相当短的调整阶段后,我们对 ArangoDB 查询语言 (AQL) 上瘾了。对我们来说,编写查询非常直观,我们可以利用各种功能和数据访问模式。 AQL 的惊人之处在于它使用嵌套的 FOR 循环来组合查询。因此,使用 AQL 编写代码和编写查询之间的过渡更加顺畅。他们的多模型方法以及在 AQL 中本地进行连接和图遍历的可能性非常好。有时在同一个查询中结合连接和遍历是很方便的。
ArangoDB 的另一个显着优势是微服务框架 Foxx。我们相当密集地使用它;我们为我们的应用程序创建了二十多个 Foxx 服务。坦率地说,Foxx 的入门有点粗糙:文档可以改进,更多示例或最佳实践会有所帮助。不过,目前,ArangoDB 团队和出色的社区支持将这种困难降到了最低。他们非常敏感和专业。这是我们决定使用数据库系统的原因之一。
目前,我们在 ArangoDB 中存储了超过 270GB 的数据(转储到磁盘 408GB)。随着数据量稳步增长,我们将很快转向三节点集群,主要是出于高可用性的原因(见下图)。
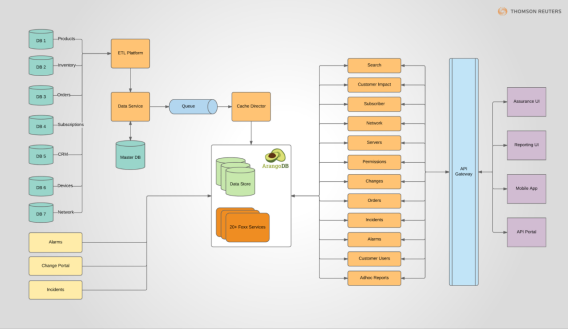
我们当前单节点设置的设置是 24 个 vCPU 和 512GB 的 RAM。 对于集群设置,我们计划为 master 使用相同的机器。
我们的应用程序本身是读/写密集型的,在高峰时段每秒至少有 3 次写入和 2 万次更新。 我们架构中的队列有助于影子写入甚至在 ArangoDB 上加载。 读取通常是稳定的; 我们预计不会出现大规模峰值。
首先,我们了解到在查询中组合不同的数据模型实际上是可能的,有时非常有帮助。查询运行速度非常快,而且 AQL 学习起来非常直观,甚至我们的产品负责人和业务分析师现在也在相对轻松地编写大量查询,有些超过两百行。有时他们不得不询问应该使用哪个索引,但大多数查询都以可接受的性能运行,无需太多额外工作。
Foxx 框架帮助我们大大缩短了开发时间。由于我们将与许多 REST 服务集成,因此我们过去常常编写大量模拟器用于集成测试。现在模拟的 REST 服务可以立即使用 Foxx 进行旋转。我们可以定义自己的路由,这样就不必将实际数据发送到客户端。相反,它可以在数据库本身内进行处理,并且只将结果发送到客户端。通过这种方法,我们可以减少很多麻烦,并在需要时提高我们的安全性。对我们来说,Foxx with ArangoDB 是一个很大的帮助,而且非常好用。
总的来说,我们现在可以将我们需要的所有数据——保证、报告、移动、API 门户——集中在一个地方,提供快速和安全的访问。 AQL 的灵活性以及不同数据模型的组合,使得运行和优化所需查询变得容易。由于 Foxx 和 AQL,扩展我们的应用程序的功能现在非常顺利。因此,我们可以将更多的时间花在实际的应用程序开发上,并更快地得到我们需要的答案。毕竟,我们被称为 The Answer Company。
非常感谢 Tanvir 抽出时间与社区分享他的经验!






