最佳实践概要
?
数据模型
Greenplum数据库是一种shared nothing的分析型MPP数据库。这种模型与高度规范化的/事务型的SMP数据库有显著区别。Greenplum数据库使用非规范化的模式设计会工作得最好,非规范化的模式适合于MPP分析型处理,例如带有大型事实表和较小维度表的星形模式或者雪花模式。
对表中用于连接的列使用相同的数据类型。
堆存储 vs. 追加优化存储
对将会接收迭代批量或者单一UPDATE、DELETE以及INSERT操作的表和分区使用堆存储。
对将会接收并发UPDATE、DELETE以及INSERT操作的表和分区使用堆存储。
对于在初始装载后很少更新并且只会在大型批处理操作中进行后续插入的表和分区,使用追加优化存储。
绝不在追加优化表上执行单个INSERT、UPDATE或者DELETE操作。
绝不在追加优化表上执行并发的批量UPDATE或DELETE操作。可以执行并发的批量INSERT操作。
行存 vs. 列存
如果负载中有要求更新并且频繁执行插入的迭代事务,则对这种负载使用行存。
在对宽表选择时使用行存。
为一般目的或混合负载使用行存。
选择面很窄(很少的列)和在少量列上计算数据聚集时使用列存。
如果表中有单个列定期被更新而不修改行中的其他列,则对这种表使用列存。
压缩
在大型追加优化和分区表上使用压缩以改进系统范围的I/O。
在数据位于的级别上设置列压缩设置。
在较高的压缩级别和压缩解压数据所需的时间和CPU周期之间做出平衡。
分布
为所有的表显式定义一个列分布或者随机分布。不要使用默认值。
使用将在所有Segment间均匀分布的单列。
不要在查询的WHERE子句中用到的列上进行分布。
不要在日期或时间戳上分布。
不要在同一列上分布并且分区表。
在常被连接起来的大型表的相同列上进行分布以显著地改进本地连接。
在初始装载数据以及增量装载数据之后验证数据被均匀分布。
根本上确保没有数据倾斜!
内存管理
把vm.overcommit_memory设置为2。
不要配置OS使用大页。
使用gp_vmem_protect_limit设置实例可以为每个Segment数据库中执行的所有工作分配的最大内存。
通过下面的计算为gp_vmem_protect_limit设置值:
gp_vmem – Greenplum数据库可用的总内存

其中 SWAP是该主机的交换空间(以GB为单位),RAM是该主机的RAM(以GB为单位)
max_acting_primary_segments – 当镜像Segment由于主机或者Segment失效而被激活时,能在一台主机上运行的最主Segment的最大数量
gp_vmem_protect_limit

转换成MB来设置配置参数的值。
在有大量工作文件被生成的场景下用下面的公式计算将工作文件考虑在内的gp_vmem因子:

绝不将gp_vmem_protect_limit设置得过高或者比系统上的物理RAM大。
使用计算出的gp_vmem值来计算操作系统参数vm.overcommit_ratio的设置:
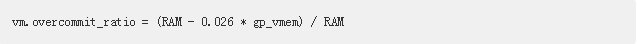
使用statement_mem来分配每个Segment数据库中用于一个查询的内存。
使用资源队列设置活动查询的数目(ACTIVE_STATEMENTS)以及队列中查询所能利用的内存量(MEMORY_LIMIT)。
把所有的用户都与一个资源队列关联。不要使用默认的队列。
设置PRIORITY以匹配用于负载以及实际情况的队列的实际需要。
确保资源队列的内存分配不会超过gp_vmem_protect_limit的设置。
动态更新资源队列设置以匹配日常操作流。
分区
只对大型表分区。不要分区小表。
只有能基于查询条件实现分区消除(分区剪枝)时才使用分区。
选择范围分区而舍弃列表分区。
基于查询谓词对表分区。
不要在同一列上对表进行分布和分区。
不要使用默认分区。
不要使用多级分区,创建较少的分区让每个分区中有更多数据。
通过检查查询的EXPLAIN计划验证查询有选择地扫描分区表(分区被消除)。
不要用列存储创建太多分区,因为每个Segment上的物理文件总数:物理文件数 = Segment数 x 列数 x 分区数
索引
通常在Greenplum数据库中无需索引。
对高基数的表在列式表的单列上创建索引用于钻透目的要求查询具有较高的选择度。
不要索引被频繁更新的列。
总是在装载数据到表之前删除索引。在装载后,重新为该表创建索引。
创建具有选择性的B-树索引。
不要在被更新的列上创建位图索引。
不要为唯一列、基数非常高或者非常低的数据使用位图索引。
不要为事务性负载使用位图索引。
通常不要索引分区表。如果需要索引,索引列必须与分区列不同。
资源队列
使用资源队列来管理集群上的负载。
将所有的角色都与一个用户定义的资源队列关联。
使用ACTIVE_STATEMENTS参数限制特定队列的成员能并发运行的活动查询数量。
使用MEMORY_LIMIT参数控制通过队列运行的查询所能利用的总内存量。
不要把所有队列都设置为MEDIUM,因为这实际上没有对负载进行管理。
动态修改资源队列以匹配负载以及现状。
监控和维护
实现Greenplum数据库管理员指南中的"推荐的监控和维护任务"。
安装时运行gpcheckperf并且在之后定期运行该工具,保存其输出用来比较系统性能随时间的变化。
使用手头的所有工具来理解系统在不同负载下的表现。
检查任何异常事件以判断成因。
通过定期运行解释计划监控查询活动以确保查询被以最优的方式运行。
检查计划以判断索引是否被使用以及分区消除是否按照预期发生。
了解系统日志文件的位置和内容并且定期监控它们,而不是只在问题出现时才去检查日志。
ANALYZE
不要在整个数据库上运行ANALYZE。需要时,有选择地在表级别上运行ANALYZE。
在装载后总是运行ANALYZE。
在显著改变底层数据的INSERT、UPDATE以及DELETE操作之后总是运行ANALYZE。
在CREATE INDEX操作之后总是运行ANALYZE。
如果在非常大的表上运行ANALYZE需要太长时间,可以只在用于连接条件、WHERE子句、SORT子句、GROUP BY子句或者HAVING子句的列上运行ANALYZE。
清扫
在大型UPDATE和DELETE操作后运行VACUUM。
不要运行VACUUM FULL。而是运行一个CREATE TABLE...AS操作,然后重命名并且删掉原始表。
频繁地在系统目录上运行VACUUM以避免目录膨胀以及在目录上运行VACUUM FULL的需要。
绝不要杀掉目录表上的VACUUM。
不要运行VACUUM ANALYZE。
装载
使用gpfdist在Greenplum数据库中装载或者卸载数据。
随着Segment数目增加最大化并行性。
在尽可能多的ETL节点上均匀散布数据。
把非常大型的数据文件分割成相等的部分,并且把数据散布在尽可能多的文件系统上。
每个文件系统运行两个gpfdist实例。
在尽可能多的接口上运行gpfdist。
使用gp_external_max_segs以控制每个gpfdist服务的Segment数量。
总是保持gp_external_max_segs和gpfdist进程的数量为偶因子。
在装载到现有表之前总是删除索引并且在装载之后重建索引。
总是在对表装载之后运行ANALYZE。
在装载期间通过设置gp_autostats_mode为NONE禁用自动统计信息收集。
在装载错误之后运行VACUUM以重新获得空间。
gptransfer
为了最快的传输率,使用gptransfer传输数据到尺寸相同或者更大的目标数据库。
避免使用--full或--schema-only选项。而是使用不同的方法将模式复制到目标数据库中,然后传输表数据。
在传输表之前删除索引并且在传输完成后重建它们。
使用SQL的COPY命令传输较小的表到目标数据库。
使用gptransfer批量传输较大的表。
在执行生产迁移之前,先测试运行gptransfer。用--batch-size和--sub-batch-size选项进行实验以得到最大并行性。为迭代运行gptransfer确定合适的表批次。
只使用完全限定的表名称。表名中的点号(.)、空格、引号(')和双引号(")都可能造成问题。
如果使用--validation选项在传输后验证数据,确定也使用-x选项在源表上放置排他锁。
确保在目标数据库上创建每一个角色、函数和资源队列。当使用gptransfer -t选项时,这些对象不会被会传输。
将postgres.conf和pg_hba.conf配置文件从源集群拷贝到目标集群。
在目标数据库中用gppkg安装所需的扩展。
安全性
保护gpadmin用户ID并且只允许对它进行必需的系统管理员访问。
在执行特定的系统维护任务(例如升级或者扩张)时,管理员只应作为gpadmin登入到Greenplum。
限制具有SUPERUSER角色属性的用户。成为超级用户的角色能绕过Greenplum数据库中的所有访问特权检查以及资源队列。只有系统管理员应该被给予超级用户的权力。请见Greenplum数据库管理员指南中的“修改角色属性”。
数据库用户绝不应该以gpadmin登录,且ETL或者生产负载也绝不应该以gpadmin运行。
为每个登入的用户分派一个不同的角色。
对于应用或者Web服务,考虑为每个应用或服务创建一个不同的角色。
使用组管理访问特权。
保护root口令。
为操作系统口令强制一种强口令策略。
确保重要的操作系统文件受到保护。
加密
加密和解密数据需要性能作为代价,只加密需要加密的数据。
在生产系统中实现任何加密方案之前,先执行性能测试。
生产Greenplum数据库系统中的服务器证书应该由一个数字证书认证机构(CA)签发,这样客户端可以认证该服务器。如果客户端都是机构中的本地客户端,CA可以是本地的。
只要客户端到Greenplum数据库的连接会通过不安全的链接,就应该对其使用SSL加密。
对称加密方案(加密和解密使用同样的密钥)具有比非对称方案更好的性能,因此在密钥能被安全共享时应当使用对称加密方案。
使用pgcrypto包中的函数来加密磁盘上的数据。数据在数据库进程中被加密和解密,因此有必要用SSL保护客户端连接以避免传输未加密数据。
在ETL数据被装载到数据库中或者从数据库中卸载时,是用gpfdists协议加密它。
高可用性
使用带有8至24个磁盘的硬件RAID存储方案。
使用RAID 1、5或6,这样磁盘阵列能容忍一个失效的磁盘。
在磁盘阵列中配置一个热后备以允许在检测到磁盘失效时自动开始重建。
通过镜像RAID卷防止重建时整个磁盘阵列失效和退化。
定期监控磁盘使用并且在需要时增加额外的空间。
监控Segment倾斜以确保数据被平均地分布并且在所有Segment上存储被平均地消耗。
设置一个后备Master以便在主Master失效后接管。
规划当失效发生时,如何把客户端切换到新的Master实例,例如,通过更新DNS中的Master地址。
设置监控机制以便在主Master失效时在系统监控应用中或者通过email发出通知。
为所有的Segment设置镜像。
将主Segment和它们的镜像放置在不同的主机上以预防主机失效。
设置监控机制以便在主Segment失效时在系统监控应用中或者通过email发出通知。
迅速地使用gprecoverseg工具失效的Segment,以便恢复冗余并且让系统回到最佳平衡。
配置Greenplum数据库发送SNMP通知给网络监控器。
在$MASTER_DATA_DIRECTORY/postgresql.conf配置文件中设置email通知,这样Greenplum系统可以在检测到严重问题时用email通知管理员。
考虑双集群配置以提供额外层次上的冗余以及额外的查询处理吞吐。
除非数据库可以很容易地从来源恢复,定期备份Greenplum数据库。
如果堆表相对较小并且两次备份之间只有很少的追加优化或列存分区被修改,使用增量备份。
如果备份被保存到本地集群存储上,在备份完成后将这些文件移动到一个安全的、不在集群上的位置。
如果备份被保存到NFS挂载点,使用例如Dell EMC Isilon之类的横向扩展NFS方案以避免IO瓶颈。
考虑使用Greenplum集成将备份流式传送给Dell EMC Data Domain或者 Veritas NetBackup企业级备份平台。






