
Nagios日志服务器 - 完整的架构概述
高层概述
Nagios Log Server 是一个为企业提供一个集中的位置来发送他们的机器生成的事件数据(例如,Windows事件日志,Linux系统日志,邮件服务器日志,网页服务器日志,应用程序日志)的应用程序,它将对消息的内容进行索引并存储数据,以便以后以近乎实时的方式进行检索,查询和分析。
一旦日志数据被索引(索引通常在到达后5秒内发生),就可以使用操作板上的图形查询和过滤工具轻松地进行分析。Log Server 包括一个快速搜索工具,它将在Google、Bing或Stack Overflow上搜索任何日志事件项目。可以根据查询创建警示,并能够通过电子邮件发送给您选择的用户。警示也可以通过NRDP发送到Nagios XI/Nagios Core,发送SNMP Trap,甚至启动一个自定义脚本。


发送到Nagios Log Server的数据可以自动归档到共享的网络驱动器上。归档后的数据可以在未来的任何时候进行恢复和重新分析。
通俗地说,这意味着它可以用来记录组织范围内所有机器和网络设备上发生的任何日志事件。Log Server的用户可以通过用户界面进行搜索,在一个中心位置访问所有这些数据。将所有数据集中在一个位置的好处是可以比较或关联来自多个设备的日志数据。此外,日志数据的自动归档将有助于维持某些标准的合规性,这些标准要求将日志数据存储不同的时间。
常见的应用案例
l 一个显而易见的应用是将日志服务器作为一个高级系统来分析接收到的日志事件,并将重要的项目(如关键错误或安全相关项目)发送到Nagios Core或Nagios XI
其他的应用案例
l 开发者可以将调试日志发送到Log Server,并轻松地过滤掉不重要的信息,只留下感兴趣的关键项目
l 企业可以利用Log Server的图形和分析功能来分析网页服务器日志,不仅可以分析错误,还可以确定哪些是常被请求的页面,访问者的地理位置,流行的浏览器等等
l 通过一个小脚本,用户可以将Nagios XI或Core的检查结果(包括性能数据)归档,并可以设置自定义的操作面板,将数据可视化(表格、柱状图、饼图等)。
l Log Server可以用来索引和归档IMAP邮箱中的信息,以保证安全或可历史参考。
l Log Server也可以接收SNMP陷阱,同样允许在接收到的陷阱上使用之前的所有功能
Nagios Log Server比基于文本系统的优点
Nagios Log Server允许将企业的所有机器生成的数据存储在一个中央位置并进行索引,允许对所有的日志数据进行查询,同时提供关联分析的能力。此外,这些数据可以以称为操作板的自定义视图的方式呈现给运行查询的用户,包括任何数据字段的结果表、条形图、饼图、折线图等。此外,日志中被确定为数字的字段可以在创建/使用图形/表格功能时进行计算,以提供总计、最小、最大、平均值等数据。

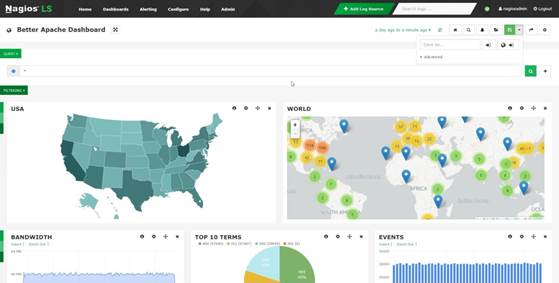
重要的术语和词汇
Nagios Log Server是由三个不同的开源组件组合而成:Elasticsearch, Logstash, Kibana. (ELK)
Elasticsearch:Log Server使用的可扩展和冗余的数据存储。
Logstash:Log Server的日志接收器--Logstash将日志输出到Elasticsearch数据库。
Kibana:ELK堆栈的可视化组件--它用于制作操作板,由表格、图形和其他元素组成。
Nagios Log Server与ELK堆栈有何不同
l 系统管理员可以花更多的时间来制作日志可视化,而不是花更少的时间来调整他们的机器。
l NLS由Nagios支持人员通过电话、电子邮件或论坛提供支持。
l NLS内置了认证和安全功能。通常情况下,ELK堆栈对任何想要查询它的人开放--这意味着系统管理员需要花时间为ELK堆栈开发保护方法。Nagios日志服务器内置了安全和认证功能。
l NLS内置了一个警报系统--你可以根据日志查询通过电子邮件发出警报。它还可以与其他几个Nagios产品结合,包括Nagios XI。
了解Elasticsearch
Elasticsearch是一个透明的组件--它不需要大量的调整,特别是当你的集群很小的时候。
Elasticsearch是首选的数据库,因为它默认是分布式和冗余的。每当一个实例被添加到你的集群中时,Elasticsearch都会通过移动各个碎片的方式确保其数据库适当地分布在所有节点上,从而提高数据的弹性。

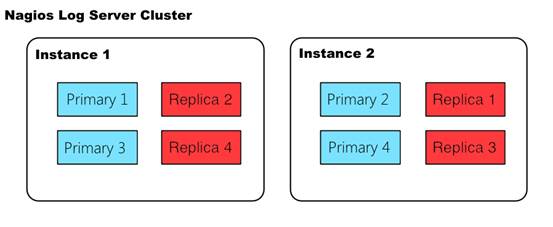
在上图中,一个集群中有两个实例。 每个实例包含两个主碎片(蓝色)和两个副本碎片(红色)。 请注意,Elasticsearch永远不会将匹配的主分片和副本分片分配给同一实例,这就是实现高可用性的方式。
了解Logstash
Logstash是Nagios日志服务器中复杂的组件,管理员必须要处理。对logstash有一个很好的理解是很有必要的。logstash代理是一个处理流水线,有3个阶段:输入->过滤->输出。输入接收传入的日志,并将这些日志传递给过滤器链,过滤器修改它们,输出将它们运送到其他地方--在我们的例子中,运送到elasticsearch数据库。


输入
输入是监听输入的日志。目前常见的三种输入是TCP、UDP和syslog。tcp输入会监听一个指定的TCP端口,并接受该端口上传来的任何日志。UDP输入也是一样的,但它会在UDP端口上监听。在syslog输入端,事情变得更加复杂--每一条进入syslog输入端的日志都会自动应用 "syslog "过滤器。作为参考,syslog过滤器是一个简单的grok过滤器,看起来像这样:
"match" => { "message" => "<%{POSINT:priority}>%{SYSLOGLINE}"
过滤器
过滤器是Logstash链中重要的部分。如果你花时间学习任何东西,请学习过滤器。如果你有正则表达式的背景,这将会有所帮助。正则表达式语法并不需要很长时间来学习,而且在生成自己的过滤器时,它对你的帮助是巨大的。网上有很多免费的教程可以学习。
Logstash 过滤器将从输入链传递下来的日志解析到你定义的 "过滤器"。在应用过滤器之前,您的日志很可能是非结构化的,并且没有应用到它们的 "字段"。过滤后,您可能会看到如下字段:

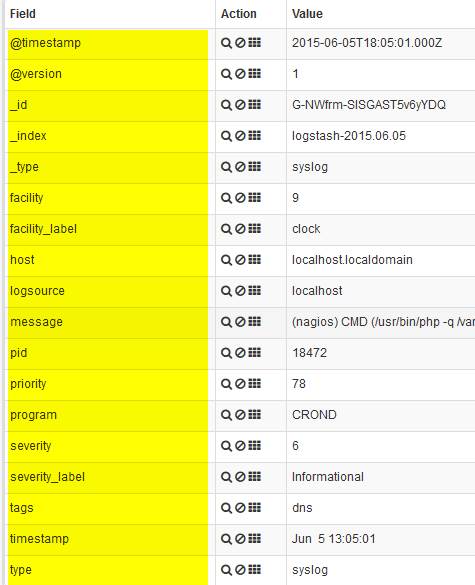
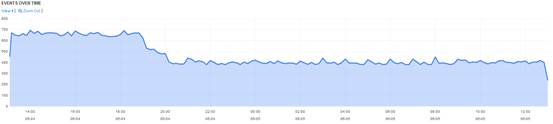
字段之所以重要,是因为它们能够创建图形和可视化:
输出
输出允许您从外部发送日志数据,这是一个更复杂的主题,并且对于Nagios Log Server功能不是必需的。