

声音分类可能是一项艰巨的任务,尤其是当声音样本的变化很小而人耳无法察觉时。机器的使用以及最近的机器学习模型已被证明是解决声音分类问题的有效方法。这些应用程序可以帮助改善诊断,并已成为心脏病学和肺病学等领域的研究主题。卷积神经网络识别COVID-19咳嗽的最新创新以及使用咳嗽记录来检测无症状COVID-19感染的MIT AI模型(https://news.mit.edu/2020/covid-19-cough-cellphone-detection-1029)显示出仅凭咳嗽声就可识别COVID-19患者的一些令人鼓舞的结果。综观这些参考资料,这项任务可能看起来颇具挑战性,就像只有顶尖研究人员才能完成的任务一样。在本文中,我们将讨论如何使用Wolfram语言中的机器学习和音频功能获得这非常有希望的结果。
使用标记的COVID-19开源咳嗽声音数据集,我们构建了一个递归神经网络,并使用梅尔频率倒谱系数(MFCC)特征提取来输入预处理的音频信号。即使我们的数据仅限于121个样本,这种方法也使我们的准确性达到了96%左右,这与不同的研究中得出的结果相似。
我们使用的数据包括121个分段的.mp3格式的咳嗽声音样本,可在此处(https://github.com/virufy/virufy_data)获取。该数据分为两类:来自COVID-19呈阳性的患者的48个样本和来自COVID-19呈阴性的患者的73个样本:

尽管样本数量不平衡,但差异很小,足以使模型仍然有效。我们使用来自于 Wolfram 函数库(https://resources.wolframcloud.com/FunctionRepository/)的TrainTestSplit 创建训练和测试集。默认情况下,它将数据分成80%的训练和20%的测试:

音频编码是音频分类的重要步骤,因为人类产生的任何声音都取决于其声道的形状(包括舌头,牙齿等)。如果可以正确确定此形状,则可以准确地表示产生的任何声音。乐器也会发生同样的情况:即使两种不同的乐器可以产生相同的声音频率,由于乐器(钢琴,吉他,长笛等)的物理特性,它们的声音也会有所不同。语音信号的时间功率谱的包络表示声道,MFCC可以准确地表示声道。某些疾病,例如肺部疾病,可能会影响空气通过我们的呼吸系统的传播方式,因此可能会导致健康患者和患病患者之间的声音差异:
最初引入MFCC来表征地震引起的地震回波。为了获得MFCC,我们首先在时域上对原始声波应用傅立叶变换,然后在结果频谱上应用幅度的对数,最后应用余弦变换。此结果频谱在同态频率域(quefrency domain)中称为倒频谱(cepstrum),既不在频域中也不在时域中。
我们将使用“AudioMFCC”(https://reference.wolfram.com/language/ref/netencoder/AudioMFCC.html)与选项 NetEncoder(https://reference.wolfram.com/language/ref/NetEncoder.html)使这整个过程是自动的。我们还可以使用“ NumberOfCoefficients”选项选择结果中所需的系数数量:

我们可以检查“ AudioMFCC”和NetEncoder应用于随机音频样本的结果。编码器的输出是大小为{ n,nc }的秩-2张量,其中n是应用预处理后的分区数,nc是用于计算的系数数:
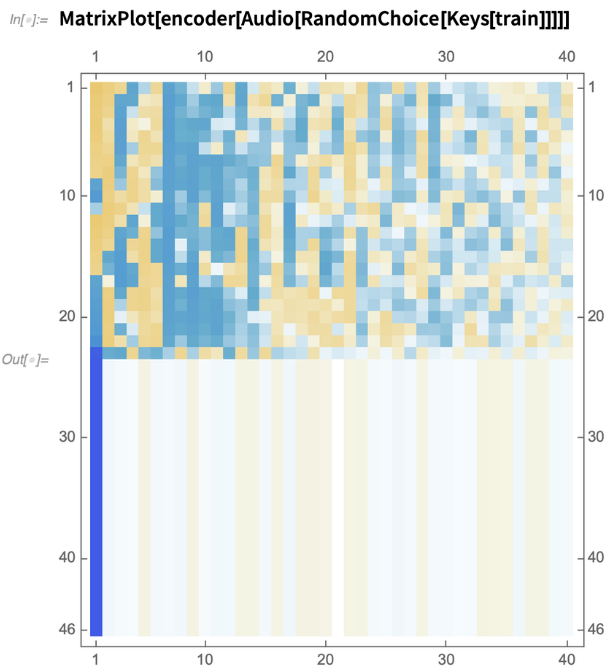
我们可以看到音频如何被转换成代表音频倒谱(cepstral )特征的矩阵。这将是我们模型的输入。我们将建立一个定制的递归神经网络(RNN),针对该神经网络手动调整超参数,并在调整-培训-评估过程中对其进行迭代。这意味着RNN将:(1)选择一组超参数;(2)训练模型;(3)评估模型;(4)重复步骤一至三。我们重复此过程,直到模型显示出较低的过拟合和较高的评估指标为止。结果是以下RNN:

我们在训练集上训练递归神经网络,并在测试集上进行验证。这使我们可以观察训练过程并调整网络的超参数,例如按顺序依次显示LinearLayer上的神经元数量,DropoutLayer 数量和序列中 GatedRecurrentLayer 的特征数量:
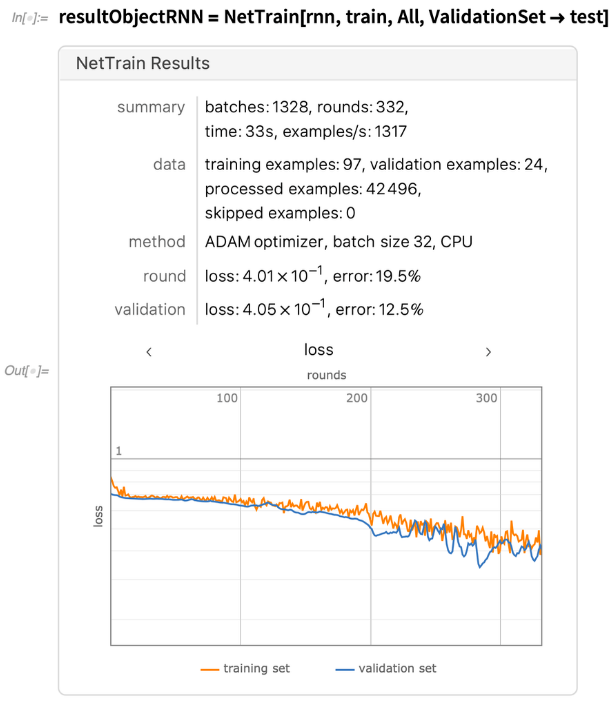
训练后,我们将对模型进行评估,将其应用于以前看不见的测试数据并评估其性能。为此,我们将尝试不同的指标:
准确性:正确预测的观测值与总观测值的比率。
F1得分:准确性和召回率的加权平均值。
精度和召回率:精度是正确预测的阳性观察值与总预测阳性观察值的比率,而召回率是正确预测的阳性观察值与实际类别中所有观察值的比率(请参见下图中的示例)。
混淆矩阵图:使我们能够看到真实的正,真实的负,假的正和假的负的预测值。
ROC曲线:告诉我们模型如何准确地区分类别(请参见下图)。负分类曲线和正分类曲线之间的重叠度越大,ROC 曲线越差。最佳ROC曲线将是一条曲线下面积(AUC)等于1的曲线。
让我们看一下模型的诊断参数:

我们还可以绘制应用于测试集的模型的混淆矩阵和ROC曲线:
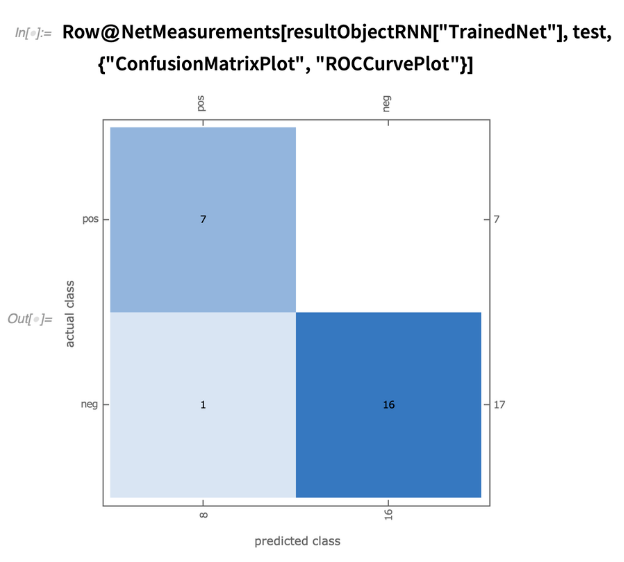
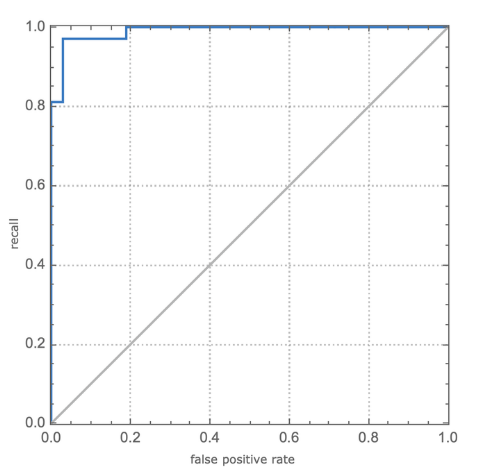
总体而言,我们通过评估的指标获得了出色的性能。他们告诉我们,该模型具有从患者的咳嗽声中正确识别或丢弃COVID-19疾病的能力。
我们构建了一个模型,该模型能够通过以大约96%的准确度对咳嗽声进行分类来检测COVID-19。这不仅显示了递归神经网络解决声音分类任务的能力,而且还显示了解决医学任务(如诊断肺部疾病)的潜力。我们能够复制MIT团队和曼彻斯特团队(https://www.researchsquare.com/article/rs-63796/v1)发布的结果。我们的数据集很小(121个样本),但是结果是有希望的,并为将来的研究提供了可能性。