
SQL 聚合函数 是执行计算并返回汇总结果的函数。有了这些,可以很容易地对数据集进行这些计算:
数数,
和,
平均数,
或获取最小值或最大值。
但还有更多。

标准偏差和方差等统计计算也是工具的一部分。将它与分组和排序相结合,您的新报告就会有一些奇妙的东西。
那么,这有多容易呢?
今天,提高您的技能,使用 SQL Server 支持的 SQL 聚合函数编写 SQL 查询。了解它们中的每一个以及何时可以使用它们。而且,当然,我们会得到实际的例子。
让我们开始吧。
SQL 计数函数
SQL COUNT就是函数名所暗示的。这很重要。
何时使用
对于您希望计入数据的任何内容。它可以是员工数量、销售产品数量或经过的天数。你说出它的名字。
SQL 中 COUNT 函数的实际示例
计算表格中的记录
学习 COUNT 的第一个也是最简单的方法是计算表中的所有记录。这包括 NULL 和重复项。

计数非空值

也可以用ALL关键字表示。

如果去掉 ALL 关键字,SQL Server 假定您的意思是 ALL。这是默认设置。
计数唯一值

如果有 2 个或更多Smith或Cruz中间名,则将其计为 1 个。
按分区或分组计数
之前的所有 COUNT 示例都返回 1 行。现在,让我们尝试对结果进行分区。

这会计算所有以 A、B、C 等开头的中间名。您可以在下面的图 1 中看到结果。
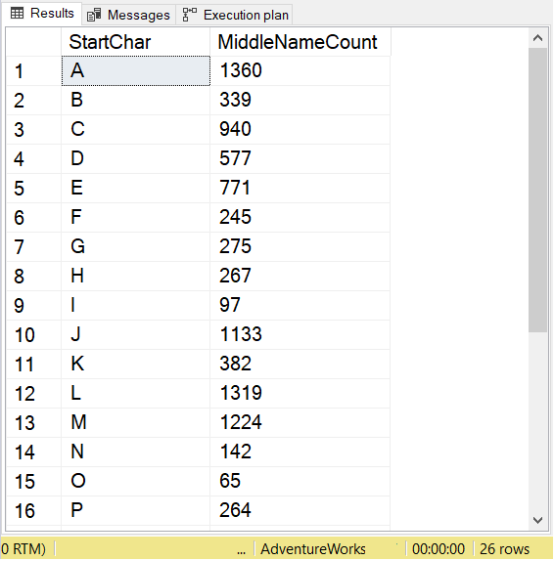
图1所示。 COUNT with OVER…PARTITION BY的结果集。
还有另一种写法可以返回相同的结果。

使用 GROUP BY 生成此查询比使用 OVER 子句更快。我们怎么知道呢?通过使用此处介绍的执行计划和 STATISTICS IO 。您可以稍后查看。
其他用于计数的 SQL 聚合函数
COUNT 返回一个 INT 数据类型。如果您需要计算高达 9,223,372,036,854,775,807 的大数据集,那么COUNT 将不起作用。您需要 COUNT_BIG。它返回一个适合计算非常大的数据集的 BIGINT 数据类型。它的功能与 COUNT 相同,但不同之处在于返回的数据类型。
COUNT(DISTINCT expression) 对于您的大数据集是否太慢?然后,使用 APPROX_COUNT_DISTINCT。它比 COUNT DISTINCT 使用更少的内存占用。它适用于具有许多不同值的大型数据集。
但是,速度有问题。
APPROX_COUNT_DISTINCT 返回近似计数。如果您需要计算大的不同的值,速度比精度更重要,就是它了。 它以 97% 的概率保证最高 2% 的错误率。
SQL SUM 函数
SUM 用于对数据集中的数值求和。
何时使用
您可以使用它来计算每月总销售额等。
SQL中SUM函数的实际例子
一段时间的格式化总和
下面是在条件下使用 SUM 的示例。结果用逗号分隔符格式化。

一段时间的组总数
此示例将添加 JOIN、GROUP BY 和 HAVING 子句的使用。请注意,您可以在 SELECT 列表和 HAVING 子句中使用 SQL 聚合函数,如 SUM。
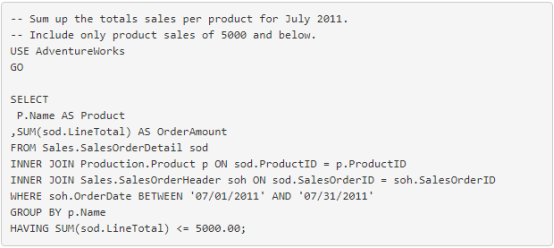

图 2. 将 SUM 与 GROUP BY 和 HAVING 子句一起使用的结果集。
SQL 平均函数
SQL AVG 函数用于获取数据集中数值的平均值。
何时使用
您可以使用它来计算以下各项的平均值:
每月销售额,
产品退货数量,
日常客户投诉,
等等。
SQL中AVG函数的实际例子
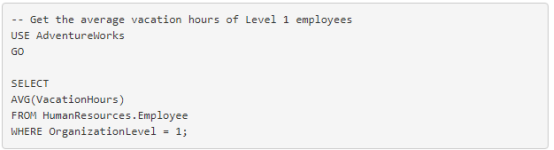
使用带条件的 AVG()
这是使用 AVG 的一个简单直接的示例。
条件与另一个 SQL 聚合函数混合的组平均值
在本例中,您可以将 AVG 与 SUM 混合使用。结果也被分组和排序。
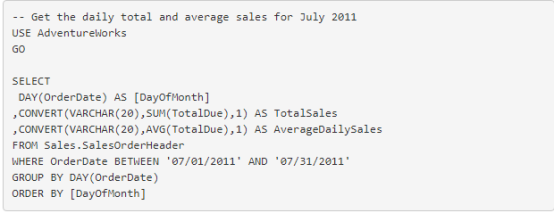
数字使用数字分隔符进行格式化。查看下面的图 3。
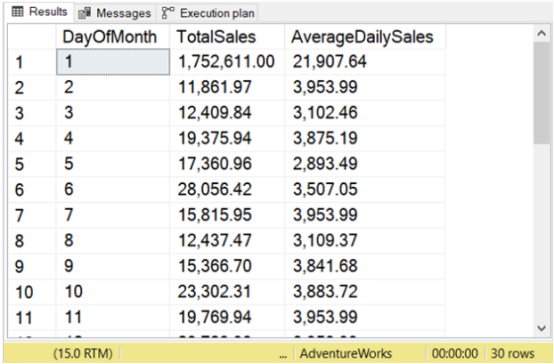
图 3. 使用 AVG() 的查询中的示例结果集。
SQL MIN 函数
使用 MIN 从一组值中获取最小值。要求和的数据可以是数字、字符串或日期。
何时使用
有利于查找最便宜的产品,当前的月薪,最早的航班等等。
SQL中MIN函数的实际例子
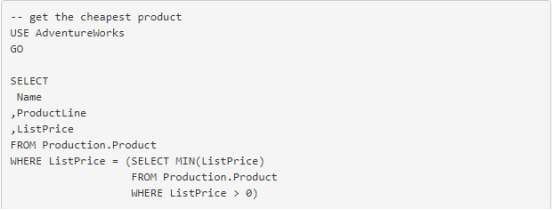
将 MIN 与子查询一起使用
将 MIN 与 GROUP BY 和 ORDER BY 一起使用
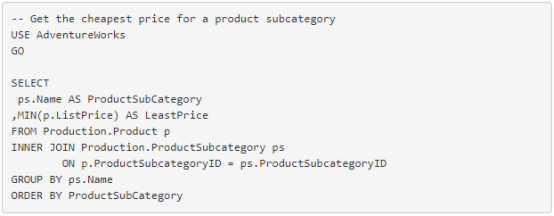

图 4. 使用 MIN 获取每个产品子类别的最低价格的查询结果集。
SQL MAX 函数
使用 MAX 获取一组值中的最大值或最后一个值。与 MIN 一样,您可以使用它来聚合数字、字符串和日期。
何时使用
这有利于获得有史以来票房最高的电影、最多的选票、最高的收入等等。
SQL MAX 函数的实际例子
将 MAX 与其他 SQL 聚合函数一起使用
您可以将MAX 与 SQL Server 中的 MIN 函数一起使用,并在一个查询中使用 COUNT。看看下面的例子。

查看下面图 5 中每个子类别的产品定价的更好视图。

图 5. 结果集显示每个子类别产品的最低和最高价格。
使用 MAX 和日期
除了数字之外,您还可以将 MAX 与日期一起使用,如下例所示。

上面的示例通过EmployeePayHistory 表中员工的最后一次费率变化获取最新的工资率 。查看下面图 6 中的结果。
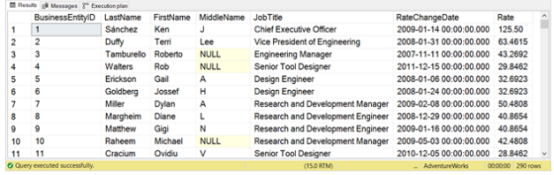
图 6. 对日期使用 MAX 函数的查询的示例结果集。
SQL 中的 VAR 和 VARP 函数
使用 SQL VAR() 获取 给定数字数据集中的代表或样本的统计方差 。同时, VARP() 是针对 数字数据集的 整个群体,因此我们在VAR之后有P。
何时使用
与 SUM 或 AVG 相比,获得方差不太常见。但在业务中,您可以在以下场景中使用它:
要知道股票是波动的还是稳定的,
如果交付产品的时间越来越短,
如果客户填写网络表单所需的时间比以前更好,
等等。
方差的结果往往被夸大。因此,测量变异性的流行选择是标准偏差。稍后会详细介绍标准偏差。
SQL 中 VAR 和 VARP 函数的实际示例
对于此项目,我们只有 1 个示例,但需要对其进行一些解释才能使其实用。
数据准备
让我们先准备数据。稍后我们将在方差和标准差示例中使用。
CREATE TABLE ServiceProviderTransactions
(
TransactionID INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
ServiceProviderID INT,
ServiceID TINYINT,
ClientID INT,
TransactionDate DATETIME,
DatePaid DATETIME,
ServiceAmount DECIMAL(6,2)
)
GO
INSERT INTO ServiceProviderTransactions
(ServiceProviderID, ServiceID, ClientID, TransactionDate, DatePaid, ServiceAmount)
VALUES
(1,1,1,'05/29/2020 00:00','06/05/2020 16:47',350.00),
(1,1,1,'06/12/2020 00:00','06/24/2020 19:22',350.00),
(1,1,1,'06/24/2020 00:00','07/02/2020 18:20',350.00),
(1,1,1,'07/14/2020 00:00','07/14/2020 22:44',350.00),
(1,1,1,'07/31/2020 00:00','08/06/2020 21:53',350.00),
(1,1,1,'08/17/2020 00:00','09/02/2020 23:11',350.00),
(1,1,1,'09/14/2020 00:00','09/14/2020 22:51',350.00),
(1,1,1,'10/02/2020 00:00','10/09/2020 23:11',350.00),
(1,1,1,'10/15/2020 00:00','10/21/2020 23:13',350.00),
(1,1,1,'10/23/2020 00:00','10/29/2020 23:58',350.00),
(1,1,1,'10/30/2020 00:00','11/09/2020 23:44',350.00),
(1,1,1,'11/06/2020 00:00','11/11/2020 15:58',350.00),
(1,1,1,'11/11/2020 00:00','11/11/2020 15:58',350.00),
(1,1,1,'11/20/2020 00:00','11/27/2020 18:13',350.00),
(1,1,1,'12/04/2020 00:00','12/15/2020 01:52',350.00),
(1,1,1,'12/11/2020 00:00','12/23/2020 01:39',350.00),
(1,1,1,'12/18/2020 00:00','12/23/2020 20:30',350.00),
(1,1,1,'01/22/2021 12:43','01/28/2021 01:02',350.00),
(1,1,1,'02/04/2021 22:23','02/09/2021 17:33',350.00),
(1,1,1,'02/05/2021 15:48','02/13/2021 00:02',350.00),
(1,1,1,'02/12/2021 13:21','02/17/2021 08:03',350.00),
(1,1,1,'02/19/2021 22:58','02/24/2021 01:27',350.00),
(1,1,1,'02/26/2021 18:26','03/09/2021 20:23',350.00),
(1,1,1,'02/26/2021 18:44','03/09/2021 20:23',350.00),
(1,1,1,'03/05/2021 13:53','03/22/2021 20:27',350.00),
(1,1,1,'03/12/2021 13:41','03/22/2021 20:27',350.00),
(1,1,1,'03/19/2021 17:32','03/24/2021 19:49',350.00),
(1,1,1,'03/26/2021 14:29','04/01/2021 18:46',350.00),
(1,1,1,'03/31/2021 19:35','04/01/2021 21:54',350.00),
(1,1,1,'04/16/2021 21:23','04/19/2021 19:44',350.00),
(1,1,1,'04/23/2021 19:04','04/27/2021 20:43',350.00),
(1,1,1,'04/30/2021 20:00','05/11/2021 21:20',350.00),
(1,1,1,'05/07/2021 21:12','05/11/2021 21:20',350.00),
(1,1,1,'05/14/2021 14:56','05/18/2021 09:38',350.00),
(1,1,1,'05/21/2021 10:12','06/01/2021 16:52',350.00)
GO
问题的简要背景
在我们进入编码部分之前,我们会问一些与这些数据相关的问题。
您的客户付钱给您,但他们需要多长时间才能付钱给您?当您被问到这样的问题时,您会回答“我平均需要 10.3542 天才能得到付款”吗?当然不是!通常的回答是,“有时我会在同一天收到报酬。但在其他日子,需要 60 天。当这种情况发生时,真是糟透了!”
当类似的情况发生在您身上时,您有同样的感觉吗?
这证明我们感觉不到平均水平。在产品交付等其他问题上也是如此。每当有交易时,您都需要 MIN 时间。但是您讨厌MAX。当交货或付款需要更长的时间时,会有一定程度的失望。
失望的程度可以使用统计方差来衡量。当需要更长的时间时,方差会增加。
您现在能理解我的意思吗?然后,让我们开始编码。
带有 VAR 和 VARP 的示例 SQL 代码
我们将检查客户 1 每月向服务提供商 1 付款所需的天数的差异。这是代码。

除了 VAR 和 VARP 之外,我们还使用了几个 SQL 聚合函数。下面的图 7 将帮助我们理解结果。
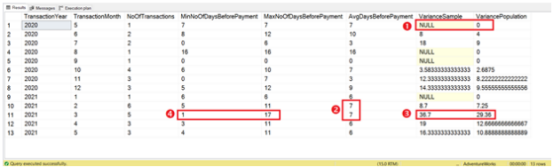
图 7. 计算方差的查询结果集。
分析
在 Client1 支付服务费用的上下文中,请注意结果中的这 4 件事。注意事项在图 7 中编号。
数据中 0 或 null 的方差很简单。仅存在 1 个事务。因此,也不存在变异。
2021 年 2 月和 3 月平均为 7 天。但是请注意它们对于样本方差和总体方差的方差有多大。这就是为什么平均日子感觉不对劲的原因。
2021 年 3 月的差异最大。方差越大,我们越说“糟透了!” 当然,这取决于您可以容忍不付款的时间。您能想象最多需要 90 到 120 天吗?
如果将#3 与#4 进行比较,您就会明白为什么 2021 年 3 月的差异最大。数据高度分散在 1 到 17 之间。
您可能会问,为什么要同时使用样本方差和总体方差?重点是什么?
在我们的例子中,重点是展示一个例子。但在现实世界中,您必须选择一个。我们的数据包含 1 个客户和 1 个服务提供商。看起来它是大型数据集的子集。如果是这种情况,样本方差就有意义了。如果我们只对 Client 1 和 Service Provider 1 感兴趣,那么这个子集就是我们唯一需要的信息。因此,这使得总体方差适用。然而,如果这是唯一的数据,那么总体方差更有意义。
但是当您说方差是 29.36 时,涉及的单位是什么?此外,等待付款的最长期限仅为17天。这就是为什么方差令人困惑而标准偏差更有意义。
SQL 中的 STDEV SQL 和 STDEVP 函数
STDEV() 返回数字数据集中代表或样本的统计标准偏差。同时,如果数据来自完整或整体人口,则使用 STDEVP()。
与方差不同,标准差处理用于计算平均值或平均值的单位。这些单位可以是天、小时、美元、点、米或任何需要的计量单位。
标准偏差是方差的平方根。它还说明一个值与平均值的距离。
何时使用
与方差一样,标准差也是可变性的度量。因此,通常的用例将起作用。不过,在其他情况下,方差更有意义,但它们超出了本文的范围。
以下是更多用例:
解读民意调查数据。
研究 45 至 65 岁男性心脏病风险标志物
了解全国调查中年龄的变化。
STDEV SQL 和 STDEVP SQL 函数的实际示例
我们的标准差示例将只是用方差扩展前面的示例。这样,我们可以将 2 与数据进行比较。

下面的图 8 显示了结果。
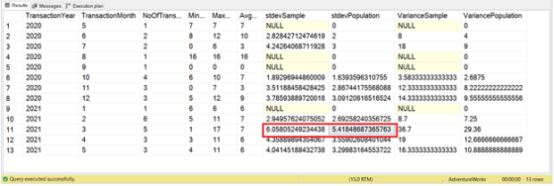
图 8. 具有标准偏差和方差的结果集。
由于标准差是方差的平方根,所以结果是一个较小的值。然而,这更接近于我们的最小值、最大值和平均值。2021 年 3 月的标准偏差(图 8 中的方框)也是最高的。其余部分讲述了与方差相同的故事。
STRING_AGG SQL 函数
STRING_AGG() 连接行中的字符串,每行之间有一个分隔符。分隔符不会添加到最后一个字符串的末尾。
何时使用
为数据集成等制作文本。
SRTING_AGG SQL 函数的实际例子
我们的示例是根据姓名、出生日期和职位名称形成以竖线分隔的文本数据。
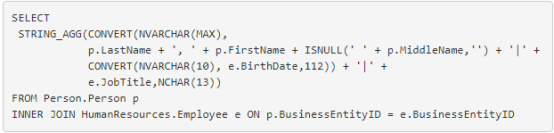
查看下面图 9 中的结果。它使用 SQL Server Management Studio 中的 数据查看器。
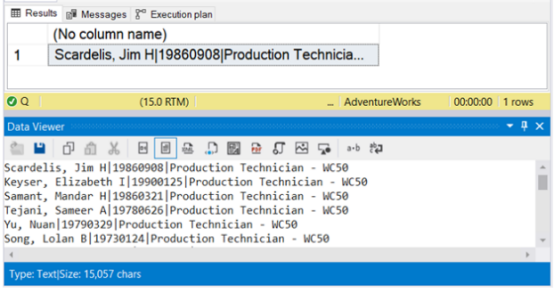
图 9. 使用 STRING_AGG 生成以竖线分隔的文本数据的结果。
CHECKSUM_AGG SQL 函数
CHECKSUM_AGG 返回数据集中值的校验和。
何时使用
您可以使用它来比较 2 个表是否相同。
SQL中CHECKSUM_AGG函数的实际例子
要使用它来比较 2 个表中的数据,让我们 从AdventureWorks 数据库中创建Products表 的临时副本。然后我们得到原件和副本的校验和。
除了 CHECKSUM_AGG(),我们还将使用 BINARY_CHECKSUM 来获取行的校验和。
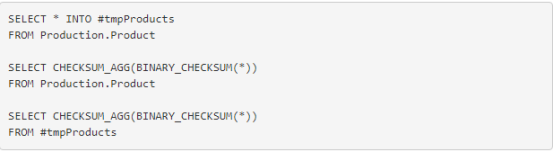
这是在做任何更改之前 2 的校验和:
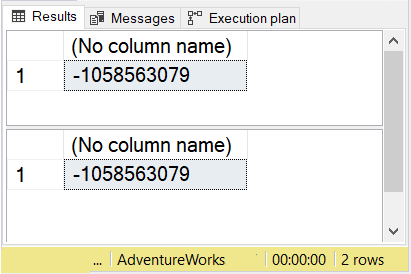
图 10. Products 表的原始和副本的校验和。校验和是一样的。
现在让我们从临时表中删除一些记录。然后,我们再次得到校验和。

删除记录后校验和的变化见图11。

图 11. 从 Products 表副本中删除记录后 CHECKSUM_AGG 的结果。
但是请注意,计算出的校验和几乎不会发生变化。
SQL 中的 GROUPING 和 GROUPING_ID 函数
如果 GROUP BY 子句中使用的指示表达式被聚合,则 GROUPING 返回 1。否则,它返回 0。
同时, GROUPING_ID 计算分组级别。
这两个函数都需要使用 GROUP BY。如果 GROUP BY 子句中没有 ROLLUP、CUBE 或 GROUPING SETS,两者都将返回零。因此,如果 GROUP BY 子句中存在这些关键字中的任何一个,则结果将是有意义的。
何时使用
当您的 SELECT 语句具有 GROUP BY 子句,并且您需要结果中的小计和总计时。
SQL 中 GROUPING 和 GROUPING_ID 函数的实际示例
要了解这是如何工作的,让我们创建一个没有这些SQL GROUPING 和 GROUPING_ID 函数的查询。
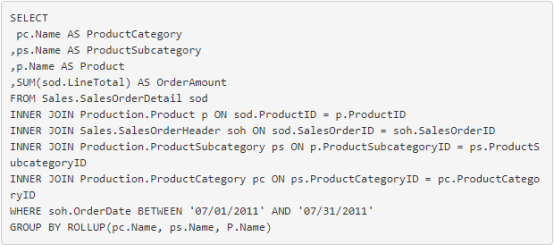
就是这样。我们在语句中有 GROUP BY ROLLUP。现在,让我们检查下面图 12 中的结果。
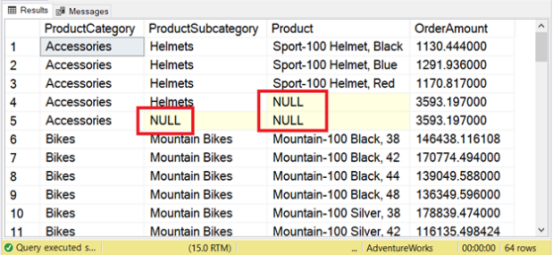
图 12. 使用 GROUP BY ROLLUP 而没有 GROUPING 和 GROUPING_ID 的查询结果。
图 12 中的那些空值是什么?
如果没有 ROLLUP,这些将不会出现。它们是总计和小计。图 12 中的方框部分是指示符。这些是头盔子类别的小计和配件类别的总计。不太像样,不是吗?GROUPING 和 GROUPING_ID 将允许您格式化这些总计和小计。
让我们在下面的代码中使用它们。

我在查询中添加了 GROUPING 和 GROUPING_ID 的输出。这些输出对于代码中的 CASE WHEN 子句很有用。让我们看看图 13 中的输出。
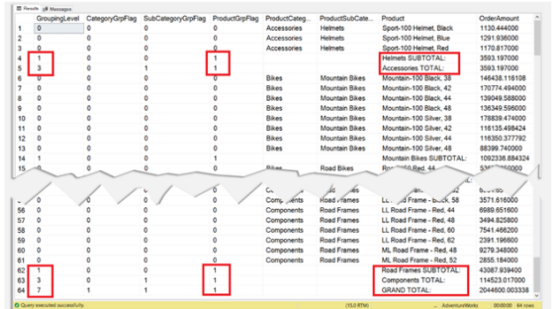
图 13. 使用 GROUP BY ROLLUP 和 GROUPING 和 GROUPING_ID 的查询结果集。
注意到图 13 中的方框部分了吗?我们在前面的代码中使用了指示的分组级别和组标志。这些级别和标志用于格式化输出、删除空值并添加更好的标题。
这好多了。
使用 SQL 聚合函数的最重要内容
那么,您对 SQL 聚合函数的了解如何?
这些函数适用于报告中的汇总计算。尽管其中一些也有其他目的。您还可以使用 GROUP BY 和 OVER PARTITION BY 对输出进行分类。然后使用 ORDER BY 进行排序。
现代 SQL 工具使与聚合函数相关的所有任务都更加简单明了。特别是,用于 SSMS的Devart SQL Complete 插件会自动计算 MIN、MAX、AVG、SUM、COUNT 和 DISTINCT 结果。您只需选择SSMS 结果网格中的单元格即可查看准确的结果。
我希望对每个函数的讨论及其实际示例对您有所帮助。
像这样?然后请在您最喜欢的社交媒体平台上分享。

Edwin Sanchez
软件开发人员和项目经理,拥有超过 20 年的软件开发经验。他最近的技术偏好包括 C#、SQL Server BI Stack、Power BI 和 Sharepoint。Edwin 将他的技术知识与他最近的内容写作技巧相结合,以帮助新一代的技术爱好者。