
Nevron Barcode for SSRS
可用于SQL Server Reporting Services 2005、2008、2008R2、2012、2014、2016和2017的最高级条形码报告项。



用于报告服务的高级线性和矩阵条形码生成器
Nevron Barcode for SQL Server Reporting Services(SSRS)旨在为报表作者提供一种简单而强大的方法来创建与数据紧密集成的线性和矩阵条形码。
如果您希望在报表中集成条形码可视化,那么Nevron barcode for SSRS是一个完美的选择。它可以显示几乎所有广泛使用的条码符号,完全由数据驱动。
Nevron Barcode for SSRS的功能:
自2008年起支持所有版本的SQL Server和Visual Studio(SSDT)
Nevron Barcode for SQL Server Reporting Services引入了新级别的数据可视化,旨在扩展SSRS 2008、2008R2、2012、2014、2016和2017版中的报表。
支持多条码区域
Nevron Barcode for Reporting Services支持无限数量的条形码区域。每个条形码区域可以显示不同的条形码符号,并且这些区域可以自动或手动排列。
支持多个标题
Nevron Barcode for Reporting Services支持无限数量的标题,可以手动定位或停靠到条形码或条形码区域。
支持条形码模板
Nevron Barcode for Reporting Services支持保存和加载模板。将条形码状态从设计器保存到XML,然后将其导入到其他报表项中。VS2005、VS2008、VS2010、VS2012、VS2013和VS2015报表项生成的状态是兼容的,这意味着您可以轻松转换使用不同版本的Visual Studio生成的报表。
Codabar

Codabar是一种线性条码符号。它及其变体也被称为Codeabar、Ames Code、NW-7、Monarch、Code 2 of 7、Rationalized Codabar、ANSI/AIM BC3-1995或USD-4。
即使在联邦快递航空账单和血库表格等多部分表格的点阵打印机上打印时,也能准确阅读该表格,截至2007年,这些表格的变体仍在使用。虽然较新的符号在较小的空间中保存更多信息,但Codabar在库中的安装基数很大。甚至可以使用打字机式的冲击式打印机打印Codabar码,这样可以在不使用计算机设备的情况下创建大量具有连续数字的代码。每次打印代码后,打印机的图章都会机械地转到下一个号码,例如在机械里程计数器中。
Code 11

Code 11是Intermec于1977年开发的条码符号。它主要用于电信业。符号可以编码由数字0-9和破折号字符(-)组成的任何长度字符串。可包括一个或多个模-11校验位。
Code 128 Auto

Code 128是一种非常高密度的条码符号。它只用于字母数字或数字条码。它可以对所有128个ASCII字符进行编码,并通过使用扩展字符(FNC4)对ISO/IEC 8859-1中定义的拉丁文-1字符进行编码。
Code 128 Subset A

Code 128 Subset A支持数字、大写字母和控制字符,例如制表符和新行(ASCII字符00到95(0-9、A-Z和控制代码)、特殊字符和FNC 1-4)。
Code 128 Subset B

Code 128 Subset B支持数字、大写和小写字母(ASCII字符32到127(0-9、A-Z、A-Z)、特殊字符和FNC 1-4)。
Code 128 Subset C

Code 128 Subset C仅支持数字(00-99(用一个代码对每两个数字进行编码)和FNC1)。
Code 39

Code 39(也称为Alpha39, Code 3 of 9, Code 3/9, Type 39, USS Code 39或USD-3)是一种可变长度的离散条码符号。
Code 39规范定义了43个字符,由大写字母(A到Z)、数字(0到9)和一些特殊字符(-, ., $, /, +, %和空格)组成。另一个字符(表示为“*”)用于开始和停止分隔符。每个字符由九个元素组成:五个条和四个空格。每个字符中的九个元素中有三个是宽的(二进制值1),六个元素是窄的(二进制值0)。窄宽比可以选择在1:2到1:3之间。
Code 93

Code 93是一种条形码符号,旨在为Code 93提供更高密度和数据安全增强。它是一个字母数字、可变长度的符号。Code 93主要由加拿大邮政公司用于对补充递送信息进行编码。每个符号包含两个校验字符。
每个Code 93字符被分为九个模块,并且总是有三个条和三个空格,因此得名。每个条和空间为1至4个模块宽。
EAN13
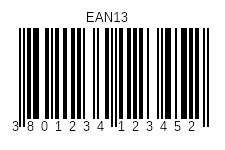
EAN-13条码(最初是欧洲商品编号,但现在改名为国际商品编号,尽管缩写EAN已被保留)是一个13位(12个数据和1个检查)条码标准,是美国开发的原始12位通用产品代码(UPC)系统的超集。
EAN-13条码中的13位数字分组如下:
EAN-13条形码在全球范围内用于标记通常在零售点销售的产品。
EAN8

EAN-8是一种条形码,源自较长的European Article Number(EAN-13)代码。在EAN-13条码太大的小包装上使用,例如香烟、铅笔(虽然很少用于铅笔)和口香糖包装。它的编码与UPC-A条码的12位相同,只是它的左右半部分各有4位(而不是6位)。
FIM (Facing Identification Mark)
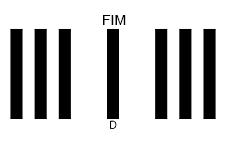
Facing Identification Mark(FIM)是美国邮政局设计的一种条形码,用于协助邮件的自动处理。FIM是印在信封或明信片上靠近上边缘的一组竖条,就在邮资区(放置邮资邮票或其等效物的区域)的左侧。本职能指令手册主要用于预印信封和明信片,由印刷信封或明信片的公司使用,而非美国邮政。
FIM是一个九位代码,由1(竖线)和0(空格)组成。以下四个代码正在使用:
FIM的作用如下。它允许取消邮件的正确正面。它还标识了邮资的支付方式(例如,商务回复邮件或基于信息的标识(IBI)邮资)以及该商务回复邮件是否具有邮政编码。如果POSTNET条码存在,邮件可以直接发送到条码分拣机。
这四个代码有以下用途:
Interleaved 2 of 5 Barcode

Interleaved 2 of 5(ITF)是连续的两宽度条码符号编码数字。它在商业上用于135胶片、ITF-14条形码和一些产品的纸箱上,而里面的产品则贴上UPC或EAN标签。
ITF编码成对的数字;第一个数字编码在五条(或黑线)中,而第二个数字编码在与之交错的五个空格(或白线)中。每5个条或空间中有2个很宽(因此正好是5个条或空格中的2个)。
ISBN

国际标准书号(ISBN)是基于9位Standard Book Numbering (SBN)代码的唯一数字商业图书标识符。10位数字的ISBN格式由国际标准化组织(ISO)开发,并于1970年作为国际标准ISO 2108发布。自2007年1月1日起,ISBN已包含13位数字,这一格式与“Bookland”欧洲商品编号EAN-13兼容。
ITF14

ITF-14(五个条码中的两个)是GS1实施的一个五个条码中的两个条码,用于编码全球贸易项目编号。ITF-14符号通常用于产品的包装。ITF-14将始终编码14位数字。
JAN13

这个符号也被称为Japanese Article Number 13,JAN-13补充5/Five-digit Add-On,JAN-13 Supplement 2/Two-digit Add-On,JAN-13+5,JAN-13+2,JAN13,JAN13+5,JAN13+2。
JAN-13(Japanese Article Numbering)条形码符号是EAN-13条形码符号的另一个名称。对于JAN条码,前两位数字必须是45或49,用于标识日本。到2013年1月要编码的值具有以下结构:
MSI Modulo 10

MSI(也称为Modified Plessey)是由MSI数据公司开发的条形码符号,基于原始的Plessey代码符号。这是一个连续的符号,不用自我检查。MSI主要用于库存控制,在仓库环境中标记存储容器和货架。
当使用Mod 10校验位算法时,将用4:12345674的校验位打印要编码的字符串1234567。
MSI 2 Modulo 10

“2 Modulo 10”方法实质上意味着MSI条形码有两个Modulo 10校验和数字。第一个Modulo 10校验和数字如上所述计算并附加到条形码。
第二个Modulo 10校验和数字通过采用新的条形码(包括第一个Modulo 10校验和数字)并重复Modulo 10校验和数字过程来计算。您实际上是在条码上执行Modulo 10校验和,条码上已经附加了一个Modulo 10校验和。此校验和数字附加在第一个校验和数字之后。
MSI Modulo 11

另一种计算校验位的方法是Modulo 11法。这种方法与计算上述Modulo 10校验位的方法明显不同。要计算Modulo 11校验位,请使用以下过程:
MSI Modulo 11 / 10

另一种实现双校验和的方法是获取原始条码,并在Modulo 11校验和数字进程中运行它。计算出的校验和随后被追加到条形码中。
新的条形码,附加了Modulo 11校验和,然后通过Modulo 10校验和过程运行。然后将计算出的校验和追加到新的条形码中,使得条形码由原始数据、后接Modulo 11校验和数字、后接Modulo 10校验和数字组成。
Pharmacode

Pharmacode,又称Pharmaceutical Binary Code,是一种条形码标准,在医药行业中用作包装控制系统。它的设计是可读的,即使打印错误。它可以多种颜色印刷,作为检查,以确保包装的剩余部分(制药公司必须印刷,以保护自己免受法律责任)正确印刷。
Pharmacode只能表示3到131070之间的单个整数。与其他常用的一维条码方案不同,Pharmacode不以与人类可读数字对应的形式存储数据;该数字是以二进制而不是十进制编码的。
Post Net

POSTNET(Postal Numeric Encoding Technique)是一种条形码符号,美国邮政局用来帮助指导邮件。邮政编码或ZIP+4编码在半高和全高条中。[1]最常见的是添加交货点,通常是地址或邮政信箱号码的最后两位数字。
条形码以一个完整的条(通常称为护栏或框架条,在USPS TrueType字体的一个版本中表示为字母“S”)开始和结束,并且在ZIP、ZIP+4或交货点之后有一个校验位。编码表显示在右侧。
每个单独的数字由一组五条表示,其中两条是完整的。
Standard 2 of 5

Standard 2 of 5是一个自检的纯数字条码。与Interleaved 2 of 5,所有信息都编码在条中;空格是固定宽度的,仅用于分隔条。Standard 2 of 5主要用于仓库分拣、照片整理和机票标记。
Telepen

Telepen是1972年在英国设计的一种条形码符号的名称,用于表示所有128个ASCII字符,而不使用移位字符进行代码切换,只使用两种不同宽度的条形图和空格。(与Code 128不同,Code 128使用移位和4种不同的元素宽度。)
与大多数线性条码不同,Telepen并不为每个字符定义独立的编码,而是在一个比特流上操作。它能够表示任何包含偶数0位的位流,并应用于偶数奇偶校验的ASCII字节,满足该规则。字节以小的字节顺序编码。
UPC-A

Universal Product Code (UPC)是一种条形码符号(即特定类型的条形码),在美国、加拿大、英国、澳大利亚、新西兰和其他国家广泛用于跟踪商店中的贸易项目。其最常见的形式是UPC-A,由12个数字组成,这些数字被唯一地分配给每个贸易项目。与相关的EAN条形码一起,UPC是根据GS1规范主要用于在销售点扫描贸易项目的条形码。
每个UPC-A条码由一条可扫描的黑色条和白色空格组成,上面是一个12位数字序列。标准UPC-A条码上不得出现任何字母、字符或其他任何类型的内容。数字和条形图保持一对一的对应关系,换句话说,只有一种方法可以直观地表示每个12位数字,只有一种方法可以用数字表示每个可视条形码。
UPC-E

为了允许在12位完整条形码可能不适合的小包装上使用UPC条形码,开发了一种“零抑制”版本的UPC,称为UPC-E,其中,制造商代码中的数字系统数字和所有尾随零以及产品代码中的所有前导零都被抑制(省略)。该符号与UPC-A的不同之处在于,它只使用6位代码,不使用中间保护条,并且结束位模式(E)变为010101。6位UPC-E与12位UPC-A的关系由最后一位(最右边的)数字确定。它只能与UPC(数字系统0或1)一起使用,UPC的值与校验位一起决定编码的奇偶校验模式。
UPC Supplemental 2-Digit

两位数的补充条形码只能用于杂志、报纸和其他此类期刊。两位数字的副刊代表杂志的发行号。这是有用的,以便产品代码本身(包含在主条形码中)是杂志的常量,这样杂志的每一期都不必有自己的唯一条形码。尽管如此,2位数字的补充可以用来跟踪杂志的哪一期正在销售,也许是为了销售分析或补充库存。
实际上,这有时是一个“内部”问题编号。两位数的分机号码并不总是和封面上的“发行号”相同。有时,编码的问题编号会随着每个问题而递增。在其他情况下,编码的期刊号可以是一年中的月份号,也可以是周号,这取决于期刊出版的频率。
UPC Supplemental 5-Digit
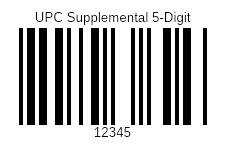
书籍上使用5位补充条形码表示建议零售价。补遗的第一位数字表示价格的货币。“0”表示以英镑表示的价格,“5”表示以美元表示的价格。补遗的其余4位数字表示价格。例如,“51195”表示建议零售价为11.95美元。补充代码“90000”表示该书没有建议零售价。补充代码“99991”表示赠书。一些出版商出于内部目的使用了90001至98999的补充代码。国家大学商店协会使用补充代码“99990”标记二手书。
QR Codes

二维码(简称快速响应码)是一种矩阵条码(或二维条码)的商标,最初是为日本汽车工业设计的。二维码使用四种标准化的编码模式(数字、字母数字、字节/二进制和汉字)来有效地存储数据;也可以使用扩展。
与标准UPC条码相比,QR码系统具有快速的可读性和更大的存储容量,因此在汽车行业之外变得非常流行。应用程序包括产品跟踪、项目标识、时间跟踪、文档管理、一般营销等。
二维码由纯色模块(正方形点)组成,这些模块(正方形点)排列在白色背景上的正方形网格中,可由成像设备(如相机)读取,并使用里德-所罗门误差校正进行处理,直到图像能够被适当解释。然后从图像的水平和垂直分量中的模式中提取所需的数据。
Data Matrix Codes

Data Matrix是一种二维矩阵条码符号,可用于对文本和数字数据进行编码。数据矩阵条形码最多可存储2,335个字母数字字符。Data Matrix条码具有很好的纠错能力,这意味着即使在条码严重损坏的情况下,也可以恢复信息。Data Matrix条码也被认为比二维码更安全,这就是为什么它们在高安全性场景(例如军事用途)中更受青睐的原因。
PDF 417 Barcode

PDF417是一种堆叠的线性条码符号格式,用于各种应用,主要是运输、识别卡和库存管理。PDF代表可移植数据文件。417表示代码中的每个模式由4个条和空格组成,每个模式的长度为17个单位。
PDF417是一种格式(连同Data Matrix),可用于打印美国邮政局接受的邮资。PDF417也被航空业的Bar Coded Boarding Pass standard(BCBP)选为纸质登机牌的二维条形码符号。PDF417是国土安全部选择的标准,作为符合真实身份的驾驶执照和国家颁发的身份证的机器可读区域技术。它也被联邦快递用于包装标签。
除了二维条码的典型特征外,PDF417的功能还包括:
下面是条形码设计器可视化显示的一些最重要的附加自定义选项的简要列表:
标题
条形码区域
渲染
外观自定义
条形码定制
Nevron Barcode for Reporting Services支持通过C#代码进行自定义。