对于使用大型语言模型的DevSecOps团队而言,MCP安全已成为首要任务。模型上下文协议(MCP)使LLM能够直接连接开发工具、本地环境及CI/CD系统,在实现强大自动化的同时,也催生了新的风险。随着这种连接日益深入,通过MCP服务器安全最佳实践实施强有力的管控变得至关重要。若缺乏适当防护,AI助手可能泄露机密信息、执行危险指令或意外修改生产环境依赖项。
本文阐述模型上下文协议的工作原理、其引入的安全漏洞,以及如何有效保障MCP服务器安全。同时展示Xygeni如何协助DevSecOps团队检测危险的AI-工具交互、实施防护措施,并在开发生命周期的每个阶段保障自动化安全。
什么是模型上下文协议(MCP)?
什么是模型上下文协议(MCP)?
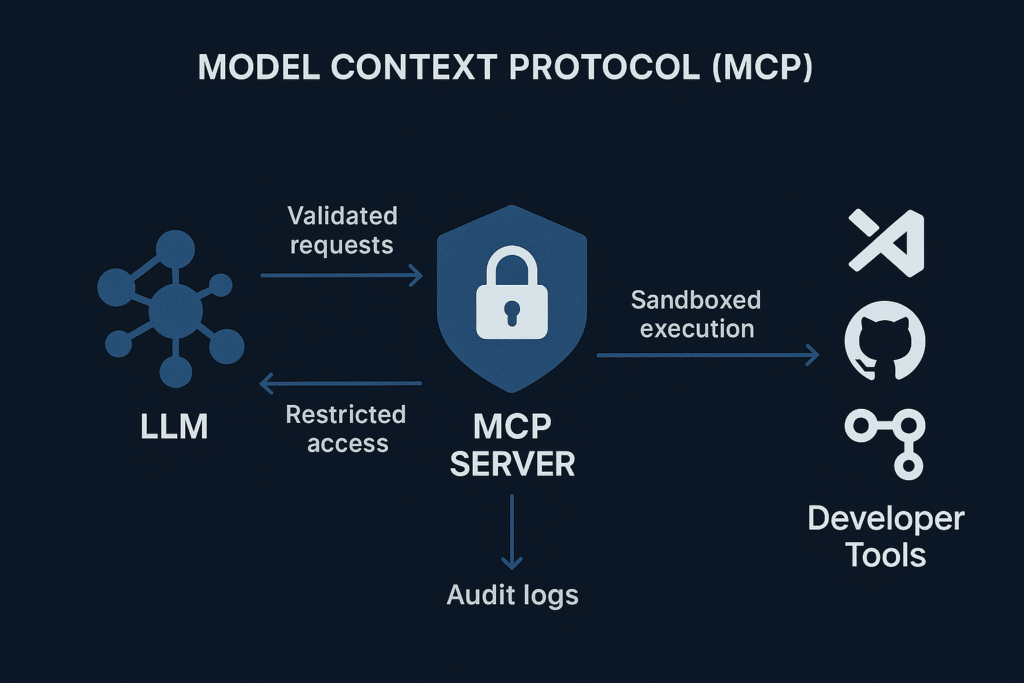
模型上下文协议定义了大型语言模型与外部开发工具间的通信层。模型不仅能以文本形式响应,还能向关联系统发送结构化请求——例如调用API、打开文件或从构建管道提取日志。
实际应用中,MCP使LLM能在开发环境中成为“主动型”助手。当开发者要求模型运行测试、检查依赖项或扫描容器时,LLM会通过MCP接口发送请求。连接的MCP服务器接收请求后,将使用授权的本地工具执行任务。
这种交互模式既节省时间又减少上下文切换,但同时也使模型暴露于本地文件路径、凭证和系统命令等敏感资源。因此MCP安全机制必须确保AI在交互过程中不越界,始终保持安全边界。
MCP服务器在LLM-DevOps集成中的运作机制
在典型架构中,MCP服务器充当LLM与开发环境间的防护桥梁。它解析模型请求、进行有效性验证,并将请求转发至可信工具(如VS Code、GitHub Actions或测试框架)。
每次请求均包含上下文信息,例如模型需访问的对象及操作目的。服务器据此判定操作是否允许。理想情况下,MCP安全层会验证该上下文以阻止不当操作。
例如:
这些检查构成了MCP服务器安全最佳实践的基础,如同防护栏般阻止模型越界操作。
MCP安全中的关键风险
尽管模型上下文协议提升了自动化水平,但也引入了多个攻击面。以下是最需重点关注的相关风险:
1. 本地暴露:若MCP服务器缺乏隔离机制,大型语言模型可能无意中访问本地文件、环境变量或敏感数据。这是最常见的MCP安全漏洞之一。
2. 密钥泄露:不安全的配置可能导致令牌、API密钥或凭证通过提示词或响应暴露。此类泄露可通过日志或模型内存迅速扩散。
3. 命令注入:由于LLM会生成文本,精心构造的提示词可能诱使模型发送恶意命令。若未进行验证,MCP服务器可能直接执行该命令。
4. 依赖项篡改:部分MCP配置允许AI自动安装或更新依赖项。若未经验证,恶意软件包可能危及本地环境。
5. 权限过高:授予AI完整系统权限可能导致不受控执行或横向移动。限制权限是MCP服务器安全的核心最佳实践之一。
上述风险均表明,模型上下文协议必须纳入组织安全边界范畴。保护API或云工作负载的安全原则现同样适用于AI-DevOps集成。
MCP服务器安全最佳实践
为构建安全可靠的MCP集成,团队应实施分层防护。以下MCP服务器安全最佳实践可有效防范常见安全事件:
|
MCP服务器安全最佳实践 |
说明 |
|
验证并净化所有请求 |
绝不直接执行模型请求。每次调用必须经过语法、意图及目标范围验证规则的检查。 |
|
限制文件系统与网络访问 |
将模型可见性限制在特定目录或端点。隔离机制可防止数据泄露并限制横向访问。 |
|
实施权限控制 |
明确定义模型可使用的工具、API及存储库。精细化访问控制确保AI活动可预测且安全。 |
|
采用容器化或沙箱化 |
在隔离环境中运行每个MCP会话。此举可防止构建或用户间的交叉污染,并限制潜在影响。 |
|
监控与审计活动 |
详细记录模型每项操作、指令及响应。监控机制支持早期事件检测与合规性验证。 |
|
轮换令牌与分离凭证 |
将模型凭证与开发密钥分开存储。频繁轮换令牌可降低凭证复用或未授权访问风险。 |
当这些MCP服务器安全最佳实践协同实施时,将构建起坚实的防护体系,使团队在享受模型上下文协议自动化优势的同时,核心系统仍能保持安全隔离。
Xygeni对MCP安全的见解
在Xygeni,安全团队将模型上下文协议视为DevSecOps领域的突破性进展与新前沿。加速代码审查的人工智能技术若缺乏管控,同样可能扩大攻击面。
Xygeni通过分析大型语言模型与开发管道的交互方式,协助企业管理这一新型风险。该平台能检测危险模式,例如通过AI提示共享机密信息,或模型指令侵入受保护环境。同时部署防护机制:阻断危险操作、限制未授权指令,并在所有MCP连接中强制执行最小权限原则。
通过持续监控与情境分析,Xygeni为每次AI-DevOps交互提供清晰可视化。这使团队更易信任AI工具,确保自动化安全运行于管道内部而非外部。
MCP安全的未来
大型语言模型在开发工具中的应用将加速普及。不久后,多数集成开发环境、构建系统和代码仓库将默认支持模型上下文协议。这一变革虽将带来生产力飞跃,却也为安全团队赋予了新责任。
随着更多AI系统直接连接源代码与基础设施,MCP安全必须成为标准DevSecOps工作流的组成部分。开发者需要可视化监控、策略执行和持续验证,确保其AI助手始终在限定范围内运作。
当前采用MCP服务器安全最佳实践的组织将安全引领这场变革。它们既能驾驭AI的速度,又不牺牲控制权与信任度。
结语
模型上下文协议使大型语言模型成为软件开发的主动参与者,将AI直接接入开发者日常依赖的工具链。然而每新增一个连接点,攻击面就会随之扩大。
通过实施严格的MCP安全管控并遵循成熟的MCP服务器安全最佳实践,团队既能释放AI驱动自动化的效益,又能保持全面掌控。
Xygeni助力企业精准实现这种平衡。其平台与现代CI/CD环境无缝集成,可识别高风险AI-DevOps流程、强制执行策略,确保每项AI操作均遵循安全设计原则。






